Básicamente tenemos dos aproximaciones que seguir para instalar un Cluster de Hadoop sobre múltiples máquinas. Una de ellas es utilizar Apache Ambari, que es la opción que describimos en el presente artículo, y que se basa en utilizar agentes para la comunicación entre el servidor de Ambari y cada uno de los servidores del Cluster. La otra opción sería utilizar Apache BigTop, que es una aproximación basada en Puppet, un rollo más DevOps.
En nuestro caso de ejemplo, vamos a realizar una instalación de un Cluster de HDP de Hortonworks sobre un único Nodo. Esto no tiene mucho sentido, lo suyo es utilizar decenas de máquinas, pero didácticamente es muy interesante, ya que permite ver y enfrentarnos a una instalación de este tipo. La experiencia va a ser muy similar.
Lo primero que tendremos que hacer es descargar el repo de Ambari, por ejemplo utilizando wget. Comprobaremos con yum repolist que ya está instalado, e iniciaremos la instalación de Ambari con yum install ambari-server (nos incluirá un PostreSQL que utiliza internamente). Una vez instalado, realizaremos la configuración inicial con ambari-server setup -s (instalación silenciosa aceptando valores predeterminados), para finalmente arrancar Ambari con el comando ambari-server start. Con esto ya tenemos Ambari. Fácil, verdad?
wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.2.0/ambari.repo -O /etc/yum.repos.d/ambari.repo
yum repolist
yum install ambari-server
ambari-server setup -s
ambari-server start |
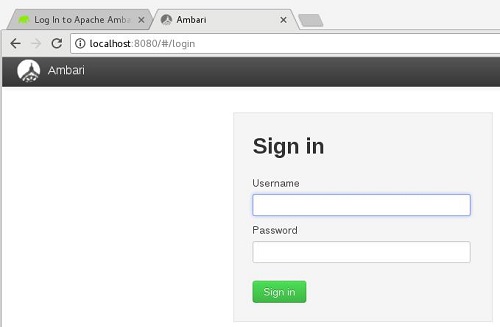
La web de Ambari por defecto escucha en el puerto 8080, así que nos conectaremos con un navegador. Nos pedirá usuario y contraseña. Por defecto es admin/admin, así nos logaremos, y cuanto antes cambiemos dicha contraseña, mejor.
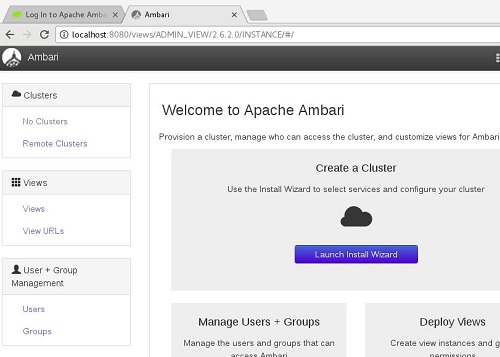
Nos encontraremos con un entorno desierto, ya que partimos de una instalación recién hecha, y necesitaremos crear nuestro Cluster. Hay varias formas, por ejemplo haciendo click en en logotipo de Ambari, en la esquina superior izquierda.
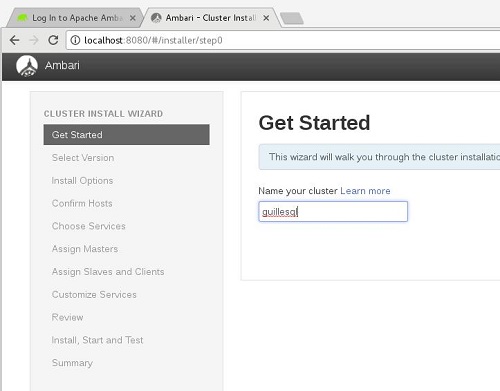
Comenzamos con la creación de nuestro Cluster. Lo primero que necesitaremos es ponerle un nombre, en mi caso guillesql, por seguir con mi tradición.
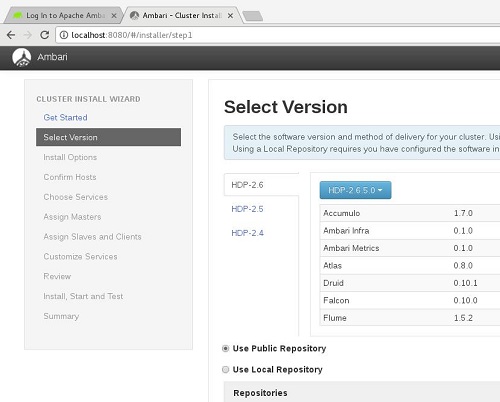
Seguidamente deberemos elegir la versión o distribución de SW que deseamos instalar, pudiendo seleccionar incluso repositorios privados. En nuestro caso utilizaremos la última versión HDP de Hortonworks del repositorio público.
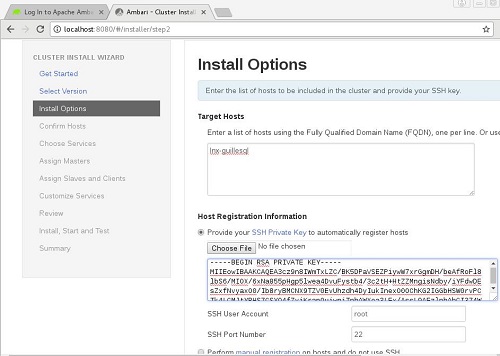
Ahora llega uno de los momentos más interesantes. Tendremos que especificar TODOS los servidores que deseamos añadir a nuestro Cluster y sobre los instalaremos unos u otros componentes de SW. En nuestro caso de ejemplo sólo lo vamos a realizar sobre un único servidor, aunque lo habitual es que sean decenas. Aquí es muy importante que tengamos correctamente configurada la resolución de nombres en todas las máquinas (ej: /etc/hosts). También es muy recomendable tener configurado el acceso por SSH con clave sin contraseña, para facilitar la ejecución de comandos remotos, etc., para lo que deberemos especificar el nombre de usuario y la clave privada.
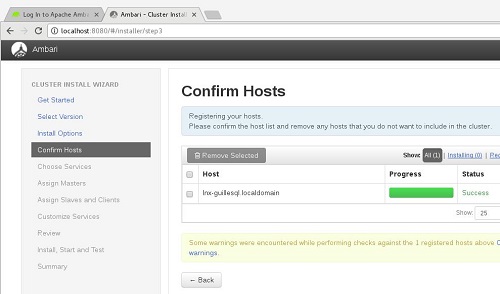
En la siguiente pantalla, podremos ver si hay algún problema con alguno de los servidores. De ser así, deberemos de hacer el debugging necesario hasta corregirlo y que esté todo en verde.
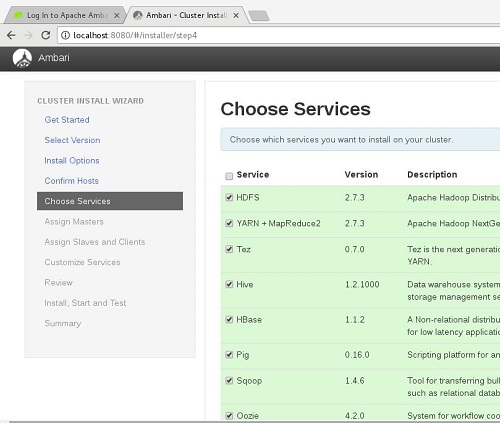
En la siguiente pantalla deberemos elegir los servicios que deseamos instalar. Aquí Ambari será un poco inteligente, en el sentido, de que si nos olvidamos algún servicio necesario (ej: dependencias con los servicios que hallamos seleccionados) nos avisará y los añadirá, por lo que nos facilitará un poco la vida, sobre todo al principio, cuando seamos beginners y estemos aún un poco perdido con tanto nombrecito raro.
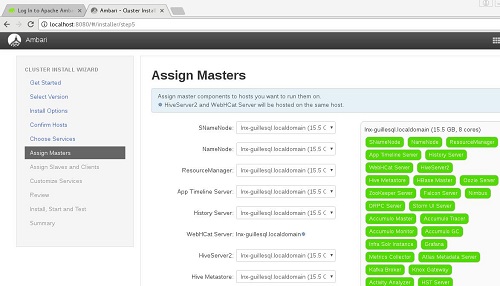
En la siguiente pantalla, Assign Masters, podremos empezar a detallar qué servicios deseamos correr en qué máquina. En nuestro caso de ejemplo, como sólo tenemos un único servidor, no cabe duda. Aceptaremos el valor propuesto por Ambari.
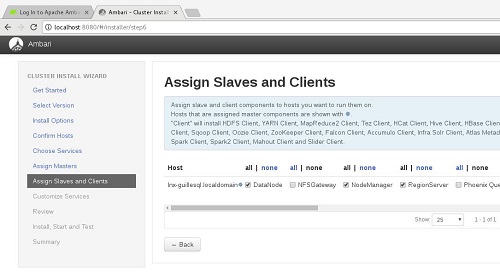
En la siguiente pantalla, Assign Slaves and Clients, continuaremos con la asignación de roles en nuestro Cluster. Volveremos a aceptar el valor propuesto por Ambari.
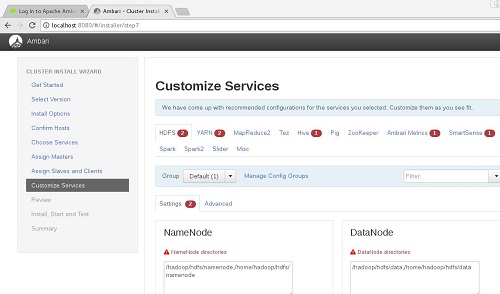
Llegaremos a la pantalla de personalización de los servicios que escogimos instalar. Aquí hay dos cosas que hacer. La primera corregir los rojos, lo errores insalvables que debemos corregir para poder continuar la instalación (básicamente, confirmar rutas y usuarios/contraseñas que deseamos utilizar). La segunda tarea a realizar, de carácter opcional (de hecho, yo no la he hecho, se puede hacer también después de instalar) es personalizar algunos parámetros de configuración de cada uno de los servicios.
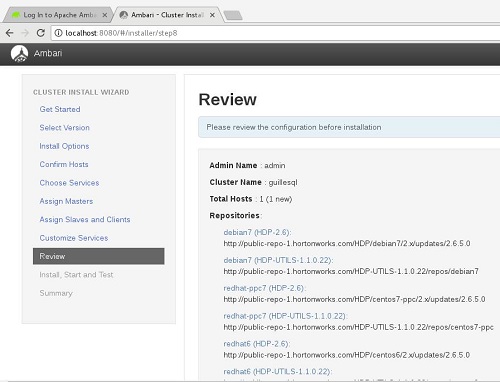
Bueno, ya estamos acabando. Revisamos el detalle de la instalación que vamos a realizar, y Deploy. Tiempo para un café.
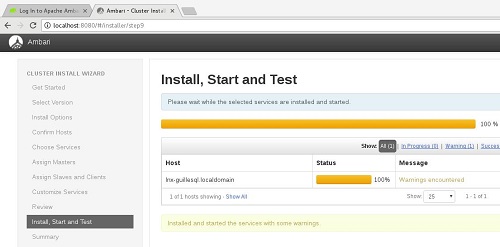
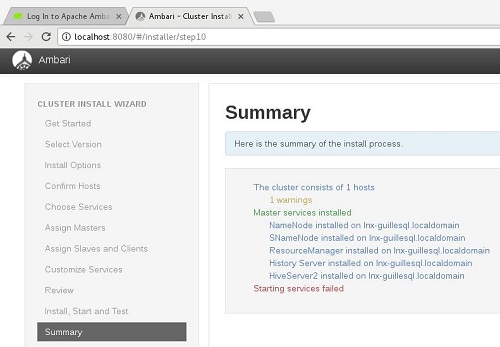
Pasado un rato, nuestra instalación habrá acabado. En nuestro caso de ejemplo ha acabado en amarillo. Cachis la mar salaa. Bueno, seguiremos adelante.
Última pantalla de la instalación. El resumen. Tenemos un Warning. La instalación se ha realizado con éxito, pero al arrancar los servicios, algunos no han sido capaces de arrancar. Bueno, no tiene muy mala pinta, mi portátil tiene ya unos cuantos añitos, quizás sólo sean unos timeouts. Vamos a verlo.
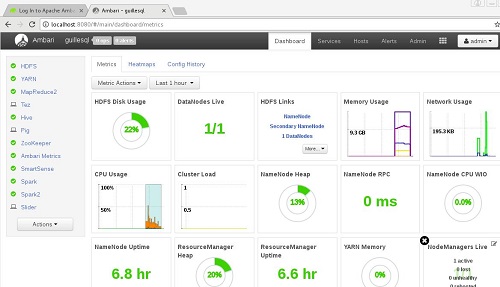
Entramos de nuevo a Ambari, y ahora aquí ya hay alguien. El problema, es que hay bastantes rojos, de servicios que están parados. Empezamos a arrancarlos, y la mayoría arrancan a la primera, todos menos Hive (tres servicios, metastore, Hive2, y HCAT). Hacemos un poquito de debugging, y parece que el principal problema está en el metastore, que no es capaz porque no encuentra el driver JDBC para conectar al MySQL que se utiliza por defecto. No es difícil encontrarlo. Una vez localizado el mensaje de error, googleando es cuestión de uno o dos minutos llegar a la solución (Hive start failed because of ambari error: mysql-connector-java.jar due to HTTP error: HTTP Error 404: Not Found). En resumidas cuentas tenemos que hacer lo siguiente:
sudo yum install mysql-connector-java*
ls -al /usr/share/java/mysql-connector-java.jar
cd /var/lib/ambari-server/resources/
ln -s /usr/share/java/mysql-connector-java.jar mysql-connector-java.jar |
Hecho esto, conseguimos arrancar Hive sin problemas. Ahora nuestro Dashboard de Ambari se muestra en verde, sin errores, como debe ser. Fácil y sencillo. Piénsalo. Sólo nos ha costado un rato montar nuestro primer Cluster de HDP Hortonworks.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.