Hacía mucho que no me encontraba con un problema tan desconcertante.
Estamos hablando de un Failover Cluster de Windows Server 2008 R2 formado por 2 Nodos, sobre el cual está corriendo un Grupo de Recursos con un FileServer (con su nombre, su IP, y sus LUNes), y dos Grupos de Recursos con SQL Server 2008 R2 y Analysis Services (es decir, cada Grupo de Recursos tiene su nombre, su IP, sus LUNes, su SQL Server, y su Analysis Services).
El recurso de FileServer se caía aleatoriamente sin motivo aparente. Incluso en alguna ocasión, aunque de forma mucho más esporádica, se caía el recurso de tipo Name (esto último dejó de ocurrir, quizás por alguna actualización).
A las instancias de SQL Server y de Analysis Services, no podías conectarte desde los propios Nodos del Cluster de forma eventual, aunque al reintentar, podías conectarte OK si hacer nada más. Bueno, al principio no sabíamos que no te podías conectar sólo desde los Nodos del Cluster, eso lo averiguamos al final.
Problemas del Recurso de FileServer
El recurso de FileServer se caía aleatoriamente sin motivo aparente (es más, y sin usuarios ni datos en la única carpeta compartida que tenía). En los eventos del Cluster, en la consola de Failover Cluster Manager, podíamos encontrar en cada caída eventos 1587 y 1069 (ambos con Source de Microsoft-Windows-FailoverClustering) asociados al recurso FileServer, que francamente, no resultaban de mucha utilidad. La información que mostraban era similar a los siguientes ejemplos:
- Event 1587 (Source de Microsoft-Windows-FailoverClustering). Cluster file server resource 'FileServer-(GuilleSQLFileServer)(Cluster Disk 10)' failed a health check. This was because some of its shared folders were inaccessible. Verify that the folders are accessible from clients. Additionally, confirm the state of the Server service on this cluster node using Server Manager and look for other events related to the Server service on this cluster node.
- Event 1069 (Source de Microsoft-Windows-FailoverClustering). Cluster resource 'FileServer-(GuilleSQLFileServer)(Cluster Disk 10)' in clustered service or application ' GuilleSQLFileServer' failed.
Además, en alguna ocasión mucho más esporádica se caía el recurso de tipo Name, encontrando los eventos 1069 y 1207 (ambos con Source de Microsoft-Windows-FailoverClustering) asociados al recurso de tipo Name. Esto ocurría sobre todo al principio. Más adelante dejaron de aparecer estos errores, aunque a saber porqué (es decir, se montaron algunas KB entre medias, se volvió a eliminar y crear el Grupo de Recursos de FileServer, se corrigieron permisos en cuentas de equipo de Directorio Activo y en registros DNS, etc.). La información que mostraban era similar a los siguientes ejemplos:
- Event 1069 (Source de Microsoft-Windows-FailoverClustering). Cluster resource 'GuilleSQLFileServer' in clustered service or application 'GuilleSQLFileServer' failed.
- Event 1207 (Source de Microsoft-Windows-FailoverClustering). Cluster network name resource 'GuilleSQLFileServer' cannot be brought online. The computer object associated with the resource could not be updated in domain 'guillesql.local' for the following reason: Unable to get Computer Object using GUID. The text for the associated error code is: The server is not operational. The cluster identity ' GuilleSQLFileServer$' may lack permissions required to update the object. Please work with your domain
Otra cosa que mosqueaba, es que en alguna ocasión, al dejar la consola de Failover Cluster Manager abierta en uno de los Nodos del Cluster (a través de una conexión RDP), más tarde, al volver a dicha sesión RDP, te encontrabas con la consola de Failover Cluster Manager sin conexión con el Cluster, es decir, algo como lo siguiente.
Creo que cuando ocurría esto, se registraba el Event 4630 (Failover Cluster Manager was disconnected from cluster 'GuilleSQLClus'. Please make sure the cluster is up and accessible), pero no estoy seguro, ya que en este evento me fijé después, y no pondría la mano en el fuego en relacionar ambas cosas.
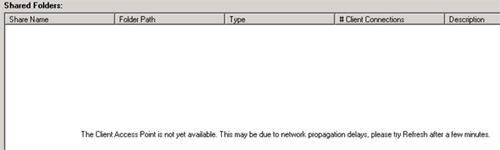
En otras ocasiones, te encontrabas en la consola de Failover Cluster Manager el mensaje de Failed to retrieve the resources in this service or application, sin conseguir mayor detalle de información (salvo la palabra unavailable por doquier), también de forma aleatoria, y tras breves instantes, se recuperaba sólo (cual Juan Palomo).
Otro mensaje de error que se podía encontrar de forma aleatoria en la consola de Failover Cluster Manager, era el siguiente: The Client Access point is not yet available. This may be due to network propagation delays, please try refresh after a few minutes.
Había otro error, que sin llegar a ser propio del FileServer, surgía la duda de cuanto podría llegar a estar relacionado con él. Se trataba del siguiente error de NetLogon, que daba la sensación de que no había ningún DC disponible, cuando todos los DCs estaban levantados y dando servicio, es más, con dos DCs en la misma VLAN en la que estaba el Cluster.
- Event 5719 (Source de NETLOGON). This computer was not able to set up a secure session with a domain controller in domain GUILLESQL due to the following: The RPC server is unavailable. This may lead to authentication problems. Make sure that this computer is connected to the network. If the problem persists, please contact your domain administrator.
En fin, esto es solo parte del muestrario de errores y mensajes sufridos por el Grupo de Recursos dedicado al FileServer.
Lo desconcertante de todo esto, es que todo parecía ser un problema de comunicaciones. Sin embargo, no había ningún problema de red (ni a nivel de los puertos de cada switch, ni a nivel de VLANs, ni a nivel de enrutamiento, ni a nivel de Firewall, ni el tamaño de MTU, etc.).
Los problemas persistían, tanto utilizando el Teaming como sin Teaming, tanto activando las opciones de TCP/UDP Offload como sin activarlas, etc.
Las versiones de los drivers de las tarjetas de red, eran las correctas. El Firmware estaba en matriz de compatibilidad. No existían problemas conocidos entre las tarjetas de red y el Switch del bastidor (enclosure), etc.
Pero aún así, seguía pareciendo un problema de red, local a la máquina, ya que la sensación era como si los Nodos del Cluster pudieran quedarse aislados (a nivel Ethernet) durante un instante, y luego recuperarse y continuar trabajando correctamente.
Sin embargo, esto no ocurría en el resto de VMs de la misma VLAN. Es más, el resto de VMs de la misma VLAN estaban accediendo OK a las instancias de SQL Server.
Problemas de conexión a SQL Server y Analysis Services
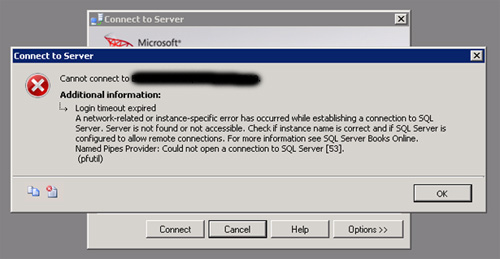
En el caso de SQL Server y Analysis Services, el tema era parecido. Conectado por RDP a los Nodos del Cluster, al conectarse con SQL Server Management Studio o con el SQL Profiler, en ocasiones (aleatoriamente) se presentaba algún error de conexión como el siguiente: Login timeout expired. A network-related or instance-specific errer has occurred while establishing a connection to SQL Server. Server is not found or not accessible. Check if instance name is correct and if SQL Server is configured to allow remote connections. For more information see SQL Server Books Online. Named Pipes Provider: Could not open a connection to SQL Server.
Sin hacer nada, al reintentar después, podías conectarte OK. Además, si había previamente alguna conexión a la instancia de SQL Server, esta no se veía afectada. Tampoco existía ningún problema de rendimiento.
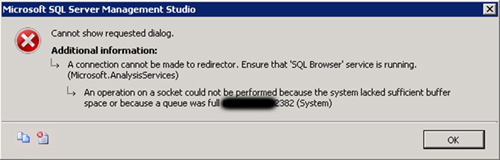
En una ocasión, conectado con el SQL Server Management Studio a una de las instancias de Analysis Services, al intentar mostrar el diálogo de propiedades de la instancia de Analysis Services, se presentó el siguiente mensaje de error: An operation on a socket could not be performed because the system lacked sufficient buffer space or because a queue was full 192.168.69.72:2382
Este error fue el único que sirvió de ayuda, al menos, para empezar a pensar en posibles problemas de comunicaciones relacionados con los Sockets, después de leer la siguiente entrada de un Blog Microsoft MSDN: Understanding the error “An operation on a socket could not be performed because the system lacked sufficient buffer space or because a queue was full.”
Al margen de todo esto, existían problemas aleatorios de conexión a SQL Server, tanto por el Software de Monitorización como por el Software de Backup. En ambos casos, existían Agentes instalados localmente en los Nodos del Cluster, que aleatoriamente tenían problemas de conexión a SQL Server, o bien problemas relacionados con Sockets. Básicamente, mostraban errores de conexión a SQL Server indicando que no se podían conectar a la instancia, como si la instancia no estuviese disponible, sin embargo todos los recursos de cada Grupo de Recursos de SQL, habían estado disponibles todo el tiempo, funcionando OK, y sin errores a nivel de SQL Server (ni el Application Log ni en el ERRORLOG).
El camino a la solución: NETSTAT, SQL Profiler y Data Collector
Entre las numerosas pruebas que tuve que hacer para obtener información de este problema, empecé a lanzar el comando NETSTAT –ano (re-direccionando la salida a un fichero, para poder comprobarlo después), en ambos Nodos del Cluster. Estuve haciendo esto durante multitud de ocasiones durante varios días. De aquí se obtuvo un dato importante: de forma aleatoria, se mostraban prácticamente todos los puertos de usuario (del 49000 al 65000 aprox en Win2008) ocupados para la dirección IP de cada Nodo del Cluster, la mayoría en estado TIME_WAIT, asociados al PID 0, y con destino la IP y puerto de la instancia de SQL Server.
De aquí, el siguiente paso relevante fue abrir una traza de SQL Server con el SQL Profiler, registrando únicamente los intentos de conexión y de desconexión a SQL Server. El resultado fue también muy interesante: prácticamente no había nada de actividad (de conexiones, quiero decir), y de pronto zas, miles de conexiones a SQL Server en un instante, cada conexión seguida de su desconexión, pero miles, todas ellas del SQL Server Agent y asociadas a la aplicación de Data Collector.
¿Podría ser que estas conexiones de los Jobs de Data Collector, que utilizan la identidad del SQL Server Agent, pudieran estar actuando como un ataque de denegación de servicio al agotar los puertos de usuario del Nodo del Cluster en el que se ejecutaba, dejándolos todos ocupados en estado TIME_WAIT durante un instante?
Nada mejor que usar el antiguo método prueba y error. Tras desactivar el Data Collector, y seguidamente desactivar los Jobs del Data Collector que aún seguían activos, fue cuestión de esperar, y voalá, tras varios días en observación, el problema quedó resuelto.
Alucinante. Así que, quería aprovechar para compartir con todos vosotros esta información, para quién le pueda resultar de interés.
Actualizado 26/07/2011. Hace pocos días me he enterado de que ya existe una KB de Microsoft que habla sobre este comportamiento y ofrece un FIX. En el caso de SQL Server 2008 R2 el FIX es montar el CU5. Por desgracia, con el CU6 el problema sigue ocurriendo (no he probado con CUs posteriores). La URL a dicha KB es la siguiente.
FIX: Upload jobs of data collector quickly open and close a large number of TCP ports if the jobs upload data to a MDW database in SQL Server 2008
Por otro lado, también he encontrado en otro Blog, información relacionada con este problema, en el cuál además se ofrece una solución alternativa (no la he probado). Aquí va la URL:
MDW Data Collection Upload may use up all available ports on a large server
Poco más por ahora. Si encuentro o averiguo algo interesante, intentaré actualizar este artículo.