Descripción del Escenario
Partimos de una instalación del PostgreSQL 9.2.18 con archivado de WAL comprimido sobre Centos7 utilizando únicamente los tablespaces por defecto. Las principales rutas son las siguientes:
- Directorio Data: /var/lib/pgsql/data
- Directorio Archivado de WAL comprimido: /var/lib/pgsql/PostgresqlWalCompr
- Directorio para almacenar los Backups: /var/lib/pgsql/PostgresqlBackup
La configuración del archivado de WAL en el fichero postgresql.conf es la siguiente:
wal_level = archive
archive_mode = on
archive_command = '/usr/local/bin/omnipitr-archive -D /var/lib/pgsql/data -l /var/log/wal/wal.log -dl gzip=/var/lib/pgsql/PostgresqlWalCompr -v "%p"' |
Sobre este escenario, vamos a realizar las pruebas que detallamos a continuación.
Preparando el Backup
Lo primero de todo vamos a hacer un Backup del filesystem a un fichero comprimido (data.tar.gz) utilizando pg_start_backup y pg_stop_backup, como ya explicamos en el anterior artículo PostgreSQL: Hot Physical Backup and Restore.
su - postgres
cd /var/lib/pgsql
psql -c "select pg_start_backup('Daily Backup'), current_timestamp"
tar -cvz -f /var/lib/pgsql/PostgresqlBackup/data.tar.gz data/
psql -c "select pg_stop_backup(), current_timestamp" |
Realizado esto, vamos a añadir en un cron una llamada a psql cada 15 minutos para insertar filas con el valor de current_timestamp en una tabla denominada test_table localizada en una base de datos llamada guillesql, para así tener información de prueba, y poder comprobar a qué momento del tiempo hemos restaurado nuestra base de datos. A continuación se muestra la sentencia psql que hemos utilizado.
| psql -d guillesql -c "insert into test_table values (current_timestamp);" |
También vamos a forzar manualmente, de vez en cuando, el rotado/archivado de los WAL, para así garantizar que tenemos diferentes WAL archivados y que en el directorio pg_xlog no queda ningún WAL, sólo los más recientes, para así probar la recuperación del archivado de WAL. Para forzar el rotado de WAL ejecutaremos lo siguiente cada vez que lo queramos forzar:
| psql -c "select pg_switch_xlog()"; |
Más tarde vamos a realizar otro backup del filesystem, igual que el anterior, pero en esta ocasión contra otro fichero (data2.tar.gz), seguiremos forzando rotados/archivados de WAL, incluso algún otro insert.
Con todo esto, tenemos completamente listo nuestro escenario para el comenzar con el restore.
Realizar el Restore a un momento del tiempo desde el Archivado de WAL
Ahora llega el momento más divertido, el de hacer el restore a un momento en el tiempo, recuperando de un Backup de filesystem y de los archivados de WAL. En nuestro caso de ejemplo, que hicimos dos Backups de filesystem en dos momentos del tiempo (a las 11:30 y a las 12:45 aprox), vamos a recuperar del primer Backup, y después vamos a recuperar las transacciones desde el archivado de WAL hasta un momento del tiempo posterior al segundo Backup del filesystem, en particular, hasta las 14:05 (imaginemos que por un problema no tenemos disponible el último Backup de filesystem… pues recuperamos del anterior y aplicamos todas las transacciones necesarias hasta el momento del tiempo al que deseamos recuperar).
Lo primero, vamos a parar PostgreSQL y a hacer un Backup del Archivado de WAL a un tar comprimido (archive.tar.gz) para garantizar que podemos volver al momento más reciente. Con esto, ya tenemos tres tar comprimidos, dos de los backups del filesystem y otro con todo el archivado de WAL (antes de parar PostgreSQL, vamos a forzar un archivado de WAL, para tener todas las transacciones hasta el último momento).
cd /var/lib/pgsql
psql -c "select pg_switch_xlog()";
pg_ctl -D /var/lib/pgsql/data -m fast stop
tar -cvzf /var/lib/pgsql/PostgresqlBackup/archive.tar.gz PostgresqlWalCompr/ |
Para continuar, tenemos que eliminar el directorio data (antes de recuperarlo del Backup de filesystem), aunque si es posible, deberíamos moverlo o hacer un Backup previo a un tar comprimido, para poder dar la marcha atrás si fuera necesario (es decir, tener un Backup en frío, con PostgreSQL parado, justo antes del Restore). Seguidamente, vamos a descomprimir el Backup de filesystem que queremos recuperar (el de las 11:30), y vamos a eliminar el contenido del directorio pg_xlog. Hecho esto, creamos el fichero recovery.conf, que es la madre del cordero.
mv data data-old # un tar comprimido también vale
tar -xvzf /var/lib/pgsql/PostgresqlBackup/data.tar.gz
rm ./data/pg_xlog/*.*
vi ./data/recovery.conf |
En el fichero recovery.conf, deberemos especificar el comando de recuperación, es decir, que comando tiene que ejecutar PostgreSQL para recuperar un WAL del Archivado (copiar, copiar y descomprimir, etc.), dependerá de que estemos haciendo para el archivado (el parámetro archive_command del fichero de configuración postgresql.conf). También especificaremos a qué momento del tiempo deseamos recuperar, en nuestro caso de ejemplo, a las 14:05.
restore_command = '/usr/local/bin/omnipitr-restore -l /var/log/wal/wal.log -s gzip=/var/lib/pgsql/PostgresqlWalCompr -f /var/lib/pgsql/data/finish.recovery -r -p /var/lib/pgsql/data/pause.removal -v -t /var/tmp/omnipitr/ %f %p'
recovery_target_time = '2017-01-26 14:05:00 CET' |
Hecho esto, ya solo queda arrancar PostgreSQL, que comprobará la existencia del fichero recovery.conf, se iniciará en modo recuperación, recuperará al momento del tiempo que le hemos indicado desde el archivado del WAL, y al finalizar renombrará el fichero recovery.conf como recovery.done y comenzará a aceptar peticiones y dar servicio. En nuestro caso de ejemplo tardó sobre un minuto. Seguidamente, comprobaremos que hemos conseguido recuperar al momento del tiempo deseado, que en nuestro caso de ejemplo, lo podemos hacer ejecutando una select contra la tabla en la que insertamos la fecha y hora cada quince minutos con el cron.
pg_ctl -D /var/lib/pgsql/data start
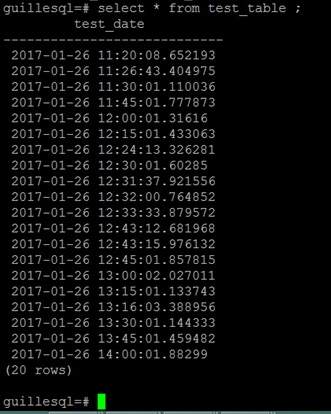
psql -d guillesql -c "select * from test_table;" |
A continuación se muestra el resultado de ejecución. Objetivo conseguido.
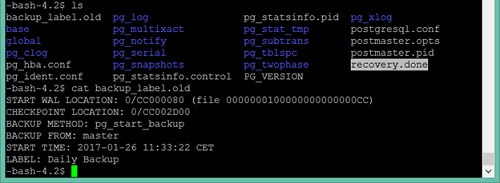
Si comprobamos el contenido del directorio data, podremos ver que el fichero recovery.conf ha sido renombrado como recovery.done al finalizar la recuperación, y también podemos observar el fichero backup_label.old que si lo visualizamos nos permitirá conocer la información básica del Backup de filesystem que hemos recuperado.
Si revisamos el LOG de PostgreSQL, podremos observar una secuencia de mensajes como la siguiente:
2017-01-26 19:22:53.249 CET,"database system was interrupted; last known up at 2017-01-26 11:33:22 CET"
2017-01-26 19:22:55.953 CET,"starting point-in-time recovery to 2017-01-26 14:05:00+01"
2017-01-26 19:22:57.096 CET,"restored log file ""0000000100000000000000CC"" from archive"
2017-01-26 19:22:57.711 CET,"redo starts at 0/CC000080"
2017-01-26 19:22:57.867 CET,"consistent recovery state reached at 0/CC003580"
2017-01-26 19:22:58.421 CET,"restored log file ""0000000100000000000000CD"" from archive"
2017-01-26 19:22:59.582 CET,"restored log file ""0000000100000000000000CE"" from archive"
2017-01-26 19:23:00.695 CET,"restored log file ""0000000100000000000000CF"" from archive"
2017-01-26 19:23:03.749 CET,"restored log file ""0000000100000000000000D0"" from archive"
2017-01-26 19:23:05.294 CET,"restored log file ""0000000100000000000000D1"" from archive"
2017-01-26 19:23:06.299 CET,"restored log file ""0000000100000000000000D2"" from archive"
2017-01-26 19:23:07.262 CET,"restored log file ""0000000100000000000000D3"" from archive"
2017-01-26 19:23:08.333 CET,"restored log file ""0000000100000000000000D4"" from archive"
2017-01-26 19:23:09.513 CET,"restored log file ""0000000100000000000000D5"" from archive"
2017-01-26 19:23:10.724 CET,"restored log file ""0000000100000000000000D6"" from archive"
2017-01-26 19:23:11.785 CET,"restored log file ""0000000100000000000000D7"" from archive"
2017-01-26 19:23:12.459 CET,"recovery stopping before commit of transaction 6613, time 2017-01-26 14:05:48.457758+01"
2017-01-26 19:23:12.459 CET,"redo done at 0/D790F400"
2017-01-26 19:23:12.459 CET,"last completed transaction was at log time 2017-01-26 14:01:40.187727+01"
2017-01-26 19:23:12.814 CET,"selected new timeline ID: 2"
2017-01-26 19:23:14.169 CET,"archive recovery complete"
2017-01-26 19:23:14.327 CET,"checkpoint starting: end-of-recovery immediate wait"
2017-01-26 19:23:20.674 CET,"checkpoint complete: wrote 2231 buffers (6.8%); 0 transaction log file(s) added, 0 removed, 1 recycled; write=0.035 s, sync=5.731 s, total=6.503 s; sync files=62, longest=0.329 s, average=0.092 s"
2017-01-26 19:23:20.894 CET,"database system is ready to accept connections" |
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.