Se trata de una situación típica, que antes o después nos encontraremos, y que con mayor o menor frecuencia se nos repetirá, con mayores o menores dolores de cabeza. Sin embargo, en SQL Server 2005 se introdujeron dos nuevos eventos de traza que nos servirán de gran ayuda para obtener información de diagnóstico en este tipo de problemas utilizando SQL Profiler: el evento Blocked process report de la categoría Errors and Warnings, y el evento Deadlock graph de la categoría Locks. Como veremos a continuación, ahora es mucho más fácil diagnosticar Problemas de Rendimiento en SQL Server.
Introducción breve a los Bloqueos (Blocks & Locks) e Interbloqueos (Deadlocks) en SQL Server
Al igual que otros muchos motores de base de datos (ej: Informix), SQL Server trabaja orientado a los Bloqueos, por lo que con los Bloqueos tenemos que acostumbrarnos a convivir. Esto significa que por defecto, todo acceso a un objeto o recurso (ej: una tabla), implica adquirir algún tipo de bloqueo (lock) como modo de protección, de tal modo, que si otro proceso intenta acceder a la vez al mismo objeto o recurso, al intentar adquirir su correspondiente bloqueo (lock), sólo lo conseguirá si intenta adquirir un tipo de bloqueo compatible (ej: dos bloqueos compartidos de lectura), mientras que de los contrario (ej: dos bloqueos incompatibles, como uno exclusivo de escritura y otro compartido de lectura), no conseguirá adquirir su bloqueo (lock) quedando bloqueado (block) y en espera (wait) de la liberación del recurso solicitado (habitualmente una página, una fila, una tabla, o un índice), una espera que en caso de prolongarse producirá una muy mala sensación de tiempo de respuesta al usuario.
El hecho de que al producirse simultáneamente intentos de bloqueos (lock) incompatibles sobre un mismo objeto o recurso, genere bloqueos (blocks) y esperas (waits) en algunos procesos, es una situación que en muchos casos deberá ser analizada para conseguir corregir muchos problemas de rendimiento de SQL Server.
Es decir, para empezar, es importante diferenciar entre adquirir un bloqueo (lock) y quedar bloqueado (block), ya que en algunos idiomas como el inglés queda más claro (palabras distintas para términos distintos), pero en otros idiomas como en el español, al utilizar una misma palabra para los dos términos (la palabra bloqueo), existe cierta confusión.
El concepto de interbloqueo (Deadlock), no deja de ser una extensión de lo anterior, pero con carácter circular (o dependencia cíclica). El caso más sencillo, es cuando una transacción T1 accede de forma exclusiva a un objeto O1 (con su correspondiente lock) mientras una transacción T2 accede de forma exclusiva a un objeto O2 (con su correspondiente lock). Hasta aquí bien, pero si a continuación la transacción T1 intenta acceder en exclusiva al objeto O2, no podrá (quedará bloqueada y en espera indefinidamente), y si simultáneamente la transacción T2 intenta acceder de forma exclusivo al objeto O1, tampoco podrá. Ambas transacciones se están bloqueando circularmente, y no hay forma de salir de este bucle. En estas situaciones de Interbloqueo (Deadlock), SQL Server elige una de las dos transacciones como víctima y la matará (kill), de tal modo, que la otra transacción pueda progresar y finalizar satisfactoriamente. Para más detalles, puede consultarse la información de Deadlocking en MSDN. Si bien, no nos queda más remedio que convivir con los Bloqueos (eso sí, minimizándolos), en el caso de Interbloqueos deberos ser capaces de conseguir la total ausencia de Interbloqueos (Deadlocks), ya que no debe producirse ninguno (objetivo: cero Interbloqueos).
Tanto los problemas de Bloqueos (Blocks & Locks) como de Interbloqueos (Deadlocks) en SQL Server, suelen aparecer especialmente en escenarios de concurrencia, y pueden ser especialmente difíciles de solucionar en escenarios transaccionales de alta concurrencia. Es decir, una aplicación es desarrollada y probada satisfactoriamente. Todo funciona a las mil maravillas. Sin embargo, a partir del día de la puesta en producción, la aplicación empieza a funcionar especialmente lenta, problemas de TimeOut, etc. Examinas que ocurre, y de pronto descubres ciertos problemas de Bloqueos (Blocks & Locks) y/o de Interbloqueos (Deadlocks). Claro, en el entorno de desarrollo y en las pruebas de preproducción realizadas, no se consiguió reproducir la concurrencia de un entorno real con usuarios, y estos problemas no aparecieron (que sutil que soy ;-). Ahora los tenemos en producción, con la presión que esto puede conllevar en ciertos entornos de alta criticidad.
Existen diferentes tipos de bloqueos (locks), ya sean compartidos o exclusivos, de lectura o de escritura, a nivel de fila o de página, a nivel de base de datos, etc. Existen diferentes niveles de aislamiento en SQL Server que pueden conseguir que se generen un mayor o menor número de bloqueos (locks, y en consecuencia, también de blocks y deadlocks) o que se mantengan durante un mayor tiempo. Existen sugerencias de tabla (table hints) y sugerencias de consulta (query hints) que podemos utilizar en nuestras consultas, y que de forma similar a los niveles de aislamiento, puede afectar a la forma en que se generan y mantienen los bloqueos (locks, y en consecuencia, también de blocks y deadlocks). Podemos configurar el tiempo máximo de espera por bloqueo para establecer un tiempo máximo de espera. Podemos optimizar nuestras consultas e índices para que su tiempo de ejecución sea más rápido (en consecuencia, menor duración de los locks, y por ello, también de los blocks y deadlocks). Podemos programar las aplicación para cachear cierta información minimizando las consultas a la base de datos (un menor número de consultas implicaría un menor número de Locks, y en consecuencia, de blocks). Podemos estar sufriendo algún problema de Parameter Sniffing que debamos corregir para minimizar el tiempo de ejecución de algunos Procedimientos Almacenados y minimizar el tiempo de los Bloqueos (locks, y en consecuencia, también de blocks y deadlocks). Es decir, existen varias alternativas que pueden resultar de ayuda para programadores y administradores de base de datos, pero en cualquier caso, necesitaremos obtener un mínimo de información de diagnóstico, que nos facilite la decisión de hacia dónde apuntar.
Consultar información de Bloqueos en tiempo de ejecución
En algunas ocasiones, será suficiente con consultar cierta información en tiempo de ejecución, para tener cierta idea del problema que está ocurriendo. Por ejemplo, en el típico caso de una consulta o proceso de larga duración que está causando bloqueos, al consultar la información en tiempo de ejecución de SQL Server (ej: consultar sys.sysprocesses y utilizar DBCC INPUTBUFFER con los procesos involucrados), puede ser suficiente para obtener una información de diagnóstico suficiente, y decidir si matar la sesión que está causando el bloqueo (Block). En este caso tenemos varias herramientas en nuestras manos, como por ejemplo:
- Los procedimientos almacenados del sistema sp_who, sp_who2, y sp_lock.
- Consultar las vistas del sistema sys.sysprocesses y sys.syslockinfo.
- El comando DBCC INPUTBUFFER.
- Consultar algunas DMV (dynamic management views) como sys.dm_exec_requests, sys.dm_exec_sessions, sys.dm_os_wait_stats, sys.dm_os_waiting_tasks, y sys.dm_tran_locks.
En otras ocasiones (ej: entornos transaccionales de alta concurrencia), puede complicarse el tema, ya que puede no tratarse de un bloqueo puntual, sino de una gran cantidad de bloqueos e interbloqueos (deadlocks) variopintos, cada uno de los cuales puede estar afectando a diferentes tablas y generando esperas de duraciones dispares. En este caso, suele resultar de gran ayuda utilizar Trazas de SQL Server, ya sea a través del SQL Profiler o a través de código, que luego puedan ser examinadas. La parte negativa, es que examinar estas trazas de SQL, en algunos casos, puede ser una tarea algo durilla, en función de cuanta información contengan (es decir, de la concurrencia, al menos en la mayoría de las ocasiones).
Breve introducción a la herramienta SQL Profiler
SQL Profiler es una herramienta gráfica que se instala junto al resto de herramientas de SQL Server. Su función principal es la de crear Trazas de SQL Server, y este es su alcance. Digo esto, porque en alguna ocasión nos puede interesar utilizar Trazas de SQL Server por un lado, y Contadores de Rendimiento por otro (ej: utilizando el Performance Monitor).
Al crear una Traza de SQL Server, existe una gran cantidad de Eventos que podemos monitorizar, y para cada Evento, estará disponible cierta información (campos). Por lo tanto, siempre que creemos una traza, deberemos seleccionar los eventos y los campos para cada evento, que nos interese para cada caso. Téngase en cuenta, que cada Evento utiliza sólo algunos campos.
Además, y esto es muy importante, las trazas de SQL Server se pueden filtrar, de tal modo podamos obtener las consultas y procedimientos almacenados ejecutados sobre una base de datos en particular, ignorando el resto.
Muchas veces, estaremos un rato jugando con el SQL Profiler, probando qué Eventos y que Campos para cada Evento son los que nos interesa capturar, estimando cuánta información nos generará por hora, evaluando la forma más eficiente de filtrar cada Evento (ojo, que se filtra por los valores de los campos, y cada Evento utiliza unos u otros campos, en la misma o diferente manera), etc. Así, conseguiremos afinar la traza o trazas que nos interesa, para finalmente ejecutar nuestra traza de SQL con el SQL Profiler.
Las trazas de SQL Profiler se arrancan, como si fueran un Job, y cuando deseemos pararlas, deberemos pausarlas o pararlas (según nos interese).
Una vez que hemos finalizado una captura de una traza de SQL con SQL Profiler, podemos examinarla con el propio SQL Profiler. Si lo deseamos, podremos guardar la traza SQL como un fichero, ya sea para enviársela a alguien (el equipo de desarrollo, el fabricante del software, etc.), o para guardarla y poder abrirla nosotros mismos más tarde (la abriremos con SQL Profiler). También la podemos guardar en una tabla de SQL Server, lo cual, tiene la ventaja de poder explotar dicha tabla con consultas de SQL (filtrar, agrupar, etc.) o incluso con informes de Reporting Services (y también desde SQL Profiler, por supuesto).
Además, una vez que tenemos definida la traza que deseamos ejecutar, desde SQL Profiler podemos generar el código Transact-SQL necesario para crear dicha traza. Esto resulta de gran utilidad, ya que podemos personalizar ese código (según nos interese), e incluso incluirlo en uno o varios Jobs de SQL Server (ej: un Job para arrancar la traza en una hora específica y otro Job para parar la traza en otra hora), y de este modo automatizar la ejecución y parada de trazas.
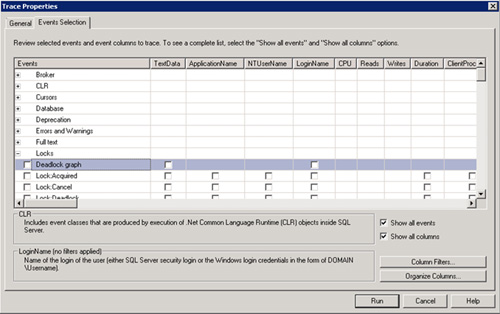
Trazas de SQL para obtener información de Interbloqueos (Deadlocks): evento Deadlock graph
Desde SQL Server 2005 se ha introducido un nuevo evento en las trazas de SQL Profiler, denominado Deadlock graph (dentro de la categoría Locks).
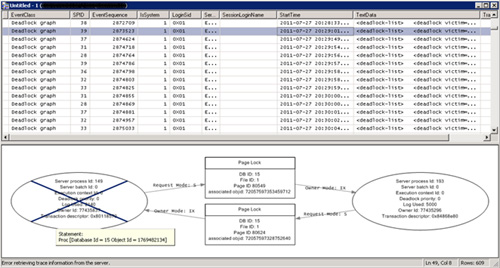
Este evento, no sólo permite obtener toda la información necesaria sobre cada interbloqueo (Deadlock), sino que además es capaz de mostrarnos la información de cada interbloqueo (Deadlock) forma gráfica, incluso al pasar el ratón por cualquiera de los procesos involucrados, se mostrará la consulta o procedimiento almacenado que estaba siendo ejecutado cuando se produjo el interbloqueo (Deadlock). Para más detalles, puede consultarse la información del evento Deadlock graph en MSDN.
El único inconveniente es que la mayoría de la información mostrada incluye identificadores internos en lugar de nombres descriptivos. Por ejemplo, en el ejemplo de la pantalla capturada anterior, podemos ver que:
- El interbloqueo (DeadLock) se produce al intentar acceder a dos páginas de dos tablas distintas, pero no aparece el nombre de las tablas, tan sólo el associated objid. Esta información la podemos obtener consultando la vista del sistema sys.partitions, filtrando por la columna partition_id, y utilizando la función del sistema OBJECT_NAME (ej: SELECT OBJECT_NAME([object_id]) FROM sys.partitions WHERE partition_id = 72057597328752640).
- Los objetos o recursos involucrados en interbloqueo (DeadLock) pertenecen a la base de datos con ID 15, pero no se muestra cuál es el nombre de esta base de datos. Esta información la podemos obtener consultando la vista del sistema sys.databases, filtrando por la columna database_id.
- Los dos procesos involucrados en el interbloqueo (Deadlock) han ejecutado un procedimiento almacenado, pero no aparece el nombre de dicho procedimiento almacenado, tan sólo el Object Id. Esta información la podemos obtener consultando la vista del sistema sys.sysobjects, filtrando por la columna id.
Existe una alternativa (parcial) a realizar estas consultas de base de datos para obtener los nombres descriptivos. Si seleccionamos un Deadlock en el SQL Profiler (es decir, una fila), le damos a copiar del menú contextual, y después a pegar en un Notepad, se nos mostrará un informe en formato XML, en el cual podremos encontrar algunos detalles adicionales, incluyendo alguna de las descripciones que andábamos buscando. También podemos utilizar la opción Extract event data del menú contextual, para obtener esta información.
Si tenemos una gran cantidad de interbloqueos (Deadlocks), el hecho de tener que resolver toda esta información de sus IDs a sus correspondientes nombres descriptivos, a priori parece que podría ser todo un infierno. Sin embargo, en la práctica, cuando tenemos una gran cantidad de Interbloqueos (DeadLocks), habitualmente estarán muy focalizados en un número muy reducido de tablas y procedimientos almacenados, por lo que muy probablemente, no resulte un trabajo tan laborioso como a primera vista podría parecer.
También es cierto, que en ocasiones nos encontraremos con interbloqueos (Deadlocks) algo más complicadillos de lo normal, como puede verse en la joya que se muestra en la siguiente pantalla capturada.
Por último, tan sólo comentar, que en ocasiones probablemente nos interesará ejecutar una traza SQL no sólo con el evento Deadlock graph, sino también incluir otros eventos que nos puedan ayudar a obtener suficiente información de diagnóstico, como para poder tomar alguna decisión.
Trazas de SQL para obtener información de bloqueos (Blocks & Locks): evento Blocked process report
De forma similar al caso anterior, desde SQL Server 2005 se ha introducido un nuevo evento en las trazas de SQL Profiler, denominado Blocked process report (dentro de la categoría Errors and Warnings).
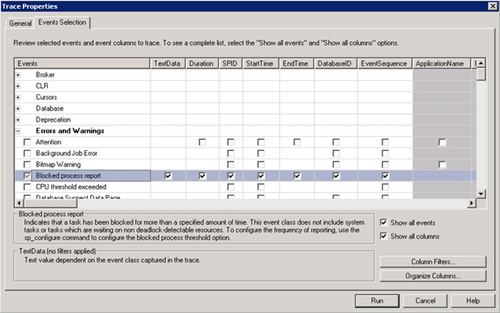
Este evento permite capturar los bloqueos existentes que han estado bloqueados al menos durante una cantidad de tiempo determinada, y especificada por la opción de configuración avanzada blocked process threshold, la cual, deberemos configurar utilizando el sp_configure (ver sp_configure en los Books-On-Line o BOL). Es importante tener en cuenta que por defecto, la opción de configuración blocked process threshold está configurada a 0, lo cual, implica que no se monitorizarán los bloqueos (si lanzamos la traza de SQL en estas condiciones, no recopilará ninguna información). Del mismo modo, deberemos considerar especificar un valor suficientemente alto para la opción de configuración blocked process threshod, por ejemplo de 10 (personalmente, intentaría con 10 o con 20, y evitaría valores menores de 10). El resultado de esta traza es un informe en formato XML con toda la información correspondiente a los bloqueos detectados. Para más detalles, puede consultarse la información del evento Blocked Process Report en MSDN, así como la información de la opción de configuración blocked process threshold.
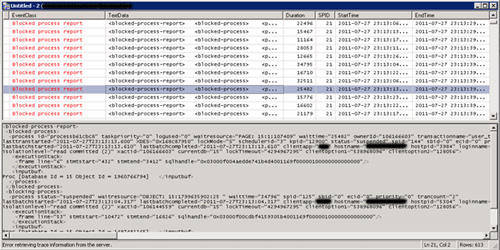
De forma similar a como nos ocurría antes con el evento Deadlock graph, cierta información necesitaremos resolverla de los IDs internos a sus correspondientes nombres descriptivos. Del mismo modo, en muchos casos nos interesará incluir en la traza de SQL otros eventos que nos puedan ayudar a obtener suficiente información de diagnóstico.
Trace Flags para DeadLocks: 1204 y 1222
No quiero entrar en esta posibilidad, simplemente, porque después de lo que acabamos de ver, resulta de poco interés (personalmente, un atraso). Sin embargo, si es interesante comentarlo, especialmente para usuarios de SQL Server 2000, los cuales no pueden aprovechar las mejoras comentadas de las trazas de SQL cara a los Bloqueos (Blocks & Locks) e Interbloqueos (Deadlocks).
Simplemente comentar que existen dos Trace Flags que podemos utilizar para obtener la información de los interbloqueos (Deadlocks) que se han producido, y que podremos utilizar desde SQL Server 2000. Para más detalles puede consultarse la información de Detecting and Ending Deadlocks en MSDN.
Otras trazas de Interés
Existen diferentes trazas que pueden resultar de interés. Personalmente, en entornos transaccionales encuentro de gran interés recoger en una traza de SQL los eventos RPC:Completed y SQL:BatchCompleted, filtrando por una duración mayor a un número determinado de segundos. En principio, filtrar por una duración mayor de un segundo debería ser apropiado para identificar procedimientos almacenados y/o consultas SQL que deberían ser optimizadas (o que están siendo partícipes de problemas de Bloques y/o Deadlocks). Por el contrario, filtrar por una duración mayor de 10 segundos debería mostrar los procedimientos almacenados y/o consultas SQL que potencialmente presentan verdaderos problemas de rendimiento o bloqueos.
¿Qué puede o debe hacer el DBA?
En la mayoría de los casos, más bien poco, básicamente la recopilación de información de diagnóstico que hemos visto, para poder facilitársela al equipo de desarrollo o al fabricante de software correspondiente, o quizás colaborar en el análisis de las trazas SQL para identificar las tablas y procedimientos almacenados en los que están focalizados la mayoría de los Bloqueos (Blocks & Locks) e Interbloqueos (Deadlocks).
Al fin y al cabo, excepto que existan problemas de acceso a disco que el DBA pueda escalar al equipo de almacenamiento, o problemas de fragmentación de índices, etc., lo recomendable es que un equipo de desarrollo o mantenimiento del producto, sea quien decida las acciones correctivas a realizar, ya sea rediseñar índices o procedimientos almacenados, sugerir la utilización del modo de aislamiento READ_COMMITTED_SNAPSHOT (algunas aplicaciones pueden tener comportamientos inesperados al utilizar este modo de aislamiento, por lo que su activación debe venir desde un equipo de desarrollo o mantenimiento del producto), modificar parte de la lógica de la aplicación, etc.
Conclusiones y Despedida
La conclusión es básicamente la recomendación de que tengamos siempre corriendo en todas nuestras instancias de SQL Server, un mínimo de trazas de SQL, que nos puede ayudar a diagnosticar problemas de rendimiento. Tener disponible esta información a priori, nos ayudará en gran manera, cuando surjan problemas y nos pidan esta información a posteriori. Las ejecuciones de consultas y procedimientos almacenados de larga duración, los Bloqueos y los Interbloqueos (Deadlocks), son parte de las trazas SQL a considerar.
Hasta aquí llega el presente artículo, que como siempre, confío que pueda resultar de interés. No puedo ocultar que este tipo de problemas generan bastantes problemas a programadores y administradores de base de datos, por lo que confío, que pueda resultar de cierta utilidad a la comunidad.