Como Denormalizar dos Tablas Versionadas (con Fecha Desde y Fecha Hasta)
|
|
Este capítulo detalla un método o algoritmo para denormalizar dos tablas versionadas (con Fecha Desde y Fecha Hasta), por supuesto, sin utilizar cursores. Esta técnica resulta de gran utilidad en entornos de Business Intelligence (BI) y Data Warehouse (DW), tanto para Reporting como para construir tablas de Dimensión en entornos OLAP. Se explica también, como para denormalizar varias tablas versionadas es posible aplicar este método o algoritmo varias veces consecutivas. Se incluyen consultas SQL de ejemplo, se detalla qué campos son estrictamente necesarios, y otras alternativas de diseño cara a la implementación de este método o algoritmo en entornos de producción de base de datos (a poder ser, con SQL Server, of course ;-). |
Un problema común al trabajar con tablas versionadas (con Fecha Desde y Fecha Hasta), es la Denormalización de Tablas Versionadas, algo que suele resultar habitual en entornos de Business Intelligence (BI) y Data Warehouse (DW), principalmente para fines de Reporting (minimizar el número de tablas utilizadas en las consultas SQL de los informes, en ocasiones permite mejorar el rendimiento, y además simplifica las consultas SQL), y también para su uso como origen de datos de Cubos OLAP (bases de datos multidimensionales, como por ejemplo, Microsoft Analysis Services).
Un ejemplo es el siguiente: si tenemos una tabla versionada (ej: CuentasCorrientes) y tenemos otra tabla versionada (ej: TitularesCuentas) que se relaciona con la primera, generar una única tabla denormalizando el contenido de ambas tablas, de tal modo que pueden darse varios casos, como por ejemplo:
- Si tenemos una Versión de una Cuenta Corriente para el periodo 01/01/2005 a 31/12/2008, y durante ese periodo existen N versiones de un titular (ej: 01/01/2004 a 01/01/2006 y 01/01/2006 a 31/12/9999), en la nueva tabla generar N versiones, cada una con la información de la Cuenta y del Titular válida para el periodo (en particular, una versión de 01/01/2005 a 01/01/2006 y otra versión del 01/01/2006 a 31/12/2008).
- Si para una Versión de una Cuenta Corriente no existe una Versión de Titular, generar para dicho periodo una Versión de la Cuenta Corriente asociada a un Titular Desconocido o No Informado.
- Si para una Versión de una Cuenta Corriente existe una Versión de Titular (o varias versiones) sólo para parte del periodo, generar para dicha parte del periodo una versión de la Cuenta Corriente asociada a dicho Titular (una o varias, es decir, tantas como versiones de Titular). Para el resto del periodo, generar una versión (o dos versiones, dependiendo de la situación) de la Cuenta Corriente asociada a un Titular Desconocido o No Informado (es lo que llamaremos, versiones superiores e inferiores, más adelante en éste capítulo). Las situaciones que pueden darse son:
- La versión del Titular (o versiones) empieza después que la versión de la Cuenta y acaba antes que la versión de la Cuenta.
Se debe generar dos versiones a Titular Desconocido o No Informado, una para cubrir el periodo sin Titular del principio, y otra para cubrir el periodo sin Titular del final.
- La versión del Titular empieza después que la versión de la Cuenta, y acaba en un momento igual o posterior a la versión de la Cuenta.
Se debe generar una versión a Titular Desconocido o No Informado para el periodo del principio en que no existe versión de Titular.
- La versión del Titular empieza en un momento anterior o igual a la versión de la Cuenta, y acaba antes que la versión de la Cuenta.
Se debe generar una versión a Titular Desconocido o No Informado para el periodo final en que no existe versión de Titular.
Para entenderlo mejor, aprovecho para incluir un gráfico que representa de modo simplificado la estructura de las dos tablas de ejemplo, resaltando los campos que más nos interesa de cada tabla: la Clave de Negocio (Business Key o BK), los campos del versionado (Fecha Desde y Fecha Hasta), un campo único (ej: una Fecha Hora de Creación, a modo de Timestamp), y la Clave Externa (Foreign Key o FK) que permite la relación entre ambas tablas.
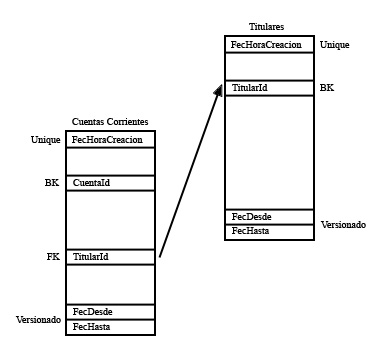 Existen diferentes métodos o algoritmos para denormalizar tablas versionadas. En este capítulo, vamos a presentar un algoritmo para denormalizar dos tablas versionadas, que funciona correctamente con el Modelo de Versionado utilizado en el presente Artículo (probado y actualmente funcionando en entornos de producción, no es sólo un ejemplo didáctico). Nótese, que en caso de tener que denormalizar más de dos tablas versionadas, podríamos utilizar éste algoritmo varias veces consecutivas (para n tablas versionadas, utilizaremos este algoritmo n-1 veces). Es decir, denormalizamos dos tablas, generando una tabla denormalizadas, y seguidamente denormalizamos dicha tabla junto a otra tabla versionada generando otra tabla más, y así sucesivamente. En cualquier caso, insisto en que éste es simplemente un método de conseguir denormalizar dos tablas versionadas, es decir, ni se trata del único método posible, ni se trata del mejor método posible. Eso sí, SIN CURSORES, OK?
Insisto en la importancia de conocer con claridad el Modelo de Versionado utilizado en este Artículo, ya que determina cómo se deben desarrollar las consultas SQL correspondientes. Si es necesario, considerar la lectura del capítulo Definición de un Modelo de Versionado.
Para el correcto funcionamiento de éste algoritmo, es vital que se cumplan las siguientes condiciones:
- No existan versiones solapadas. Es decir, para una entidad de la tabla (ej: un Titular en la tabla de Titulares) no puede existir ningún periodo de tiempo, para el que exista más de una versión válida.
- Todas las versiones de un mismo elemento, deben formar un conjunto continuo. Es decir, si tomamos la primera de las versiones (la que tiene Fecha Desde menor), todas las versiones posteriores tienen Fecha Desde igual a Fecha Hasta de la versión inmediatamente anterior. Dicho de otro modo, entre dos versiones no existe un periodo de tiempo que no esté cubierto por ninguna versión. Esta es una de las condiciones del Modelo de Versionado utilizado en este Artículo, pero debido a su importancia para el funcionamiento de éste algoritmo, aprovecho para recordarlo.
Llegados a este punto, vamos a empezar con la denormalización. Lo primero, recordar que al denormalizar dos tablas, tomaremos una de las tablas como la tabla Padre (en el ejemplo anterior, éste papel le corresponde a la tabla de Titulares), y a la otra tabla la denominaremos tabla Hija (en el ejemplo anterior, este papel le corresponde a la tabla de Cuentas Corrientes), de tal modo que, siendo puristas, nuestro objetivo es denormalizar las versiones de la tabla Hija en función de las versiones existentes en la tabla Padre. Deberemos seguir dos pasos:
- PASO 1) Generar las versiones con Hijo y Padre conocidos, o con sólo el Hijo conocido (y ningún Padre válido o conocido). Es decir, generar todas las versiones correspondientes a las versiones del Hijo (ej: Cuentas Corrientes) para las cuales, o bien existe alguna versión del Padre (generando tantas filas como versiones conocidas del Padre – ej: Titulares), o bien no existe ninguna versión del Padre (generando una única fila con el Padre – ej: Titulares – a desconocido o no informado). Esto se consigue fácilmente en una consulta SQL con un LEFT JOIN entre las tablas Hijo y Padre (evidentemente), teniendo en cuenta:
- Para realizar el JOIN (en nuestro caso, LEFT JOIN o LEFT OUTER JOIN), utilizaremos la Clave Externa (Foreign Key o FK) de la tabla Hija (ej: Cuentas Corrientes) contra la Clave de Negocio (Business Key o BK) de la tabla Padre (ej: Titulares). Con esto, cada fila o versión de la tabla Hija la relacionaremos con todas las filas o versiones de la tabla Padre (ej: Titulares). Sin embargo, esto NO es lo que queremos (es parcialmente correcto), ya que necesitamos relacionar cada versión de la tabla Hija (ej: Cuentas Corrientes) SÓLO con las versiones de la tabla Padre (ej: Titulares) que se solapen en el tiempo conforme al valor de sus campos Fecha Desde y Fecha Hasta (es decir, conforme al valor de sus campos de versionado).
- Opcionalmente, podemos excluir las filas con Fecha Desde igual a Fecha Hasta, tanto de las versiones de la tabla Hija (que lo podemos hacer fortaleciendo la cláusula WHERE, como se muestra en el siguiente ejemplo) como de las versiones de la tabla Padre (lo cual podemos hacer fortaleciendo la cláusula ON del LEFT JOIN, como se muestra en el siguiente ejemplo. Personalmente, en entornos de Data Warehouse (DW) y Business Intelligence (BI), soy partidario de excluir las filas con Fecha Desde igual a Fecha Hasta (a fin de cuenta, es información válida para un periodo de tiempo igual al conjunto vacío, es decir, es información que no es válida en ningún momento del tiempo), excepto en dos casos: que el usuario desee poder acceder a este detalle histórico de cambios, o bien, que esta consulta SQL se desee utilizar para realizar cargas incrementales. En función de cómo se desarrollen las cargas incrementales, de cómo se relacionen entre sí las diferentes tablas denormalizadas, y en consecuencia en función también de cómo se construyan campos únicos en dichas tablas denormalizadas, con el paso del tiempo se podrían producir múltiples versiones abiertas (es decir, versiones solapadas, dios mío!! ;-), por ejemplo, como causa de modificaciones de versiones con efecto retroactivo. Es complicado entenderlo fácilmente si no me explico más, pero prefiero dar este pequeño toque de atención, y continuar con el contenido propio del alcance del artículo.
- Podemos seleccionar los campos deseados de la tabla Hijo (ej: Cuentas Corrientes) y de la Tabla Padre (ej: Titulares), teniendo en cuenta que al estar realizando un LEFT JOIN, para las filas no coincidentes de la tabla Padre, nos puede interesar controlar dicha situación (ej: utilizando la función ISNULL de SQL Server) para insertar un valor con significado de Desconocido o No Informado (a algunos les gusta mantener los nulos, pero personalmente, soy anti-nulos y anti-cursores... ahora, pa gustos hay colores).
En la consulta SQL deberemos calcular los nuevos campos Fecha Desde y Fecha Hasta. Es decir, si para una versión de la tabla Hija, existen varias versiones en la tabla Padre, deberemos crear varias versiones en la tabla denormalizada (lo que hablábamos antes, no?), y para cada una de éstas filas generadas deberemos calcular su Fecha Desde y Fecha Hasta, para que las nuevas versiones generadas no se solapen. Esto se consigue fácilmente utilizando un CASE en SQL Server.
También es necesario incluir los campos Fecha Desde y Fecha Hasta del Hijo, ya que los utilizaremos en el siguiente paso para generar los intervalos inferiores y superiores de versiones Desconocidas o No Informadas. Del mismo modo, puede resultar útil incluir los campos Fecha Desde y Fecha Hasta del Padre (ej: para facilitar la depuración de errores), pero no es estrictamente necesario.
Del mismo modo, es necesario incluir un campo único de la tabla Hijo (ej: FecHoraCreacion), que utilizaremos en el siguiente paso para generar los intervalos inferiores y superiores de versiones Desconocidas o No Informadas.
Seleccionados los campos que acabo de indicar, somos libres de incluir el resto de campos que nos interesen, como las Claves de Negocio (Business Key o BK) o cualquier otro campo, tanto de la tabla Hijo como de la tabla Padre. Eso sí, llegados a éste punto debemos plantearnos si en la consula que estamos construyendo deseamos:
- Incluir todos los campos que necesitamos, generando en la consula SQL que estamos desarrollando, el conjunto de resultados definitivo.
- Incluir sólo el menor número de campos posibles, es decir, Fechas Desde, Fechas Hastas, y campos únicos, de tal modo, que depositando dichos campos en una tabla temporal (ej: utilizando SELECT INTO en nuestra consulta SQL), podamos más adelante realizar un INNER JOIN entre dicha tabla temporal y las tablas que estamos desnormalizando, para así obtener el conjunto de resultados definitivo.
Bueno, ya es suficiente, así que aprovecho para incluir una consulta SQL de ejemplo. Ojo, que aunque en la consulta SQL de ejemplo utilizo INSERT INTO, siendo puristas sería más interesante SELECT INTO, para así aprovechar las mejoras de rendimiento propias de las Operaciones de Registro Mínimo (ej: SELECT INTO, BULK INSERT, y BCP.EXE), pero en cualquier caso ese tipo de detalles está fuera de alcance en el presente artículo.
INSERT INTO dbo.TablaDenormalizada
(
CuentaId
,TitularId
,FecHoraCreacionHijo
,FecHoraCreacionPadre
,FecDesde
,FecHasta
,FecDesdeHijo
,FecHastaHijo
)
SELECT
Hijo.CuentaId
,ISNULL(Padre.TitularId, '0') AS TitularId
,Hijo.FecHoraCreacion AS FecHoraCreacionHijo
,ISNULL(Padre.FecHoraCreacion, '00010101') AS FecHoraCreacionPadre
,CASE -- Nueva Fecha Desde de la versión denormalizada
WHEN Padre.FecDesde > Hijo.FecDesde THEN Padre.FecDesde
ELSE Hijo.FecDesde
END AS FecDesde
,CASE -- Nueva Fecha Hasta de la versión denormalizada
WHEN Padre.FecHasta < Hijo.FecHasta THEN Padre.FecHasta
ELSE Hijo.FecHasta
END AS FecHasta
,Hijo.FecDesde AS FecDesdeHijo
,Hijo.FecHasta AS FecHastaHijo
FROM dbo.CuentasCorrientes AS Hijo
LEFT JOIN dbo.Titulares AS Padre
ON Hijo.TitularId = Padre.TitularId -- Business Key y FK
AND Padre.FecHasta > Hijo.FecDesde -- Versionado
AND Hijo.FecHasta > Padre.FecDesde -- Versionado
AND Padre.FecDesde < Padre.FecHasta -- Opcional: Excluir cambios duración 0
WHERE Hijo.FecDesde < Hijo.FecHasta –- Opcional: Excluir cambios duración 0
|
Por último, antes de entrar en el PASO 2, quería referirme al Gráfico de Línea de Tiempo que vimos anteriormente en este Artículo. Lo primero, indicar que la anterior consulta SQL, equivale a la expresión 3 del Gráfico de Línea de Tiempo, es decir, d>a AND c<b AND c<d AND a<b. Por ello, si nos fijamos en el Gráfico de Línea de Tiempo, la columna exp3 nos indica el número de filas de versión (ya denormalizadas) que genera como resultado la utilización de ésta expresión para realizar el JOIN (mejor dicho, LEFT JOIN) entre la tabla Hija y la tabla Padre. En consecuencia, si nos fijamos en los casos con varias filas de versión en la tabla Padre, la columna exp3 nos indica un número mayor de 1 (tantas como versiones de la tabla Padre, con Fecha Desde estrictamente menor que Fecha Hasta). Del mismo modo, si quisiéramos incluir en nuestra tabla denormalizada las versiones con Fecha Desde y Fecha Hasta, utilizaríamos la expresión 2, es decir, d>a AND c<b. Si comparamos las columnas exp2 y exp3 del Gráfico de Línea de Tiempo, podemos comprobar que evidentemente el número de filas devueltas al exp2 es mayor o igual que al utilizar exp3, dependiendo de la existencia o no de filas de versión con Fecha Desde a Fecha Hasta. Por supuesto, equivocarnos en los signos de comparación aquí se paga muy caro, como se puede ver en la expresión 1, en la que al incluir el comparador de igualdar produce un resultado incorrecto en algunos casos.
- PASO 2) Generar las versiones correspondientes a los intervalos superiores e inferiores con el Padre desconocido. En el paso anterior generamos todas las versiones con Hijo y Padre conocidos, con sus correspondientes Fecha Desde y Fecha Hasta. Además, también generamos las versiones con Hijo conocido y Padre Desconocido. Sin embargo, si nos fijamos, nos falta algo: Si tenemos una versión de la tabla Hija, y para la misma tenemos una versión relacionada de la tabla Padre, pero dicha versión de la tabla Padre empieza en un momento posterior que la versión de la tabla Hija, ¿Cómo generamos la versión correspondiente al periodo de tiempo inicial en que el Padre era desconocido? Efectivamente, este caso no estaba cubierto en la consulta SQL del paso anterior. Del mismo modo, también será necesario generar las versiones correspondientes a los periodos de tiempo finales en que el Padre era desconocido (es decir, la versión o versiones del Padre finalizan antes de la finalización de la versión del hijo), aunque este último caso no debería devolver ningún resultado en nuestro Modelo de Versionado, ya que para cada Clave de Negocio (Business Key o BK) siempre debe existir una versión abierta (es decir, con Fecha Hasta igual a +infinito, en nuestro caso, 31/12/9999).
Ahora que hemos descrito cuál es nuestro problema ¿Cómo los resolvermos? ¿Cómo desarrollar una consulta SQL o varias consultas SQL que nos permitan generar los intervalos superiores e inferiores con el Padre desconocido? La solución es muy sencilla.
Para obtener las versiones de los intervalores inferiores con Padre desconocido, es necesario realizar una consulta SQL sobre la tabla denormalizada del paso anterior, agrupando (GROUP BY) por el campo único del hijo (ej: FecHoraCreacion). Esto sin más, nos devolverá una fila por cada fila existente en la tabla Hijo (ojo, que en la tabla denormalizada generada en el paso anterior, puede haber varias filas fruto del LEFT JOIN), lo cual no es suficiente. Por ello, deberemos obtener la menor Fecha Desde y la menor Fecha Desde del Hijo, es decir, MIN(FecDesde) y MIN(FecDesdeHijo). Con esto seguiremos teniendo una fila para cada fila de la tabla Hijo, pero hemos identificado los valores para los campos del versionado (Fecha Desde y Fecha Hasta), de tal modo, que en los casos en que NO es necesario generar los intervalos inferiores, los valores de MIN(FecDesde) y MIN(FecDesdeHijo) serán iguales. Por ello, para acabar será necesario agregar una cláusula HAVING para filtrar el resultado final de la consulta SQL, generando sólo las filas necesarias.
La forma de obtener las versiones de los intervalos superiores con Padre desconocido, es similar a la anterior (los intervalos inferiores), sólo que en este caso necesitaremos utilizar la función de agregado MAX sobre otros campos del versionado, pero se trata del mismo razonamiento.
Y con esto, después de la chapa que os acabáis de tragar, aprovecho para incluir las consultas SQL de ejemplo. Ojo, se trata sólo de consultas SELECT con los mínimos campos necesarios, es decir, ni se trata de SELECT INTO o INSERT INTO, ni incluyo el otros campos que podrían ser necesarios (ej: Claves de Negocio).
SELECT
FecHoraCreacionHijo,
MIN(FecDesde) AS FecDesde,
MIN(FecDesdeHijo) AS FecHasta,
FROM dbo.TablaDenormalizada
GROUP BY FecHoraCreacionHijo
HAVING MIN(FecDesde) < MIN(FecDesdeHijo)
SELECT
FecHoraCreacionHijo,
MAX(FecHasta) AS FecDesde,
MAX(FecHastaHijo) AS FecHasta,
FROM dbo.TablaDenormalizada
GROUP BY FecHoraCreacionHijo
HAVING MAX(FecHasta) < MAX(FecHastaHijo)
|
Una vez más quería referirme al Gráfico de Línea de Tiempo que vimos anteriormente en este Artículo. En esta ocasión, voy a explicar las columnas NI e ISI del Gráfico de Línea de Tiempo. En primer lugar, la columna NI indica el número de filas de versión con Padre No Informado que se deben generar, para que la tabla denormalizada que estamos generando sea correcta y completa. Por ejemplo, en el primer caso (de Versiones Padre Periodos Simples) deberemos generar dos versiones, una desde la Fecha Desde del Hijo hasta la Fecha Desde del Padre, y otra desde la Fecha Hasta del Padre hasta la Fecha Desde del Hijo. Por otro lado, la columna ISI representa el número de Intervalos Superiores e Inferiores con el Padre desconocido que se generan en este paso (el PASO 2). Por lo tanto, el valor de la columna NI siempre será mayor o igual a la columna ISI, debido a dos motivos: Cuando no existe ningún Padre conocido, la versión correspondiente se genera desde el PASO 1 como causa de la utilización del LEFT JOIN, por lo tanto, no se genera en el PASO 2; Además, en el caso de "Versiones Padre Periodos Compuestos Discontinuos", los periodos intermedios con Padre desconocido (es decir, No Informado) se incluyen (es decir, se contabilizan) en la columna NI (porque sería necesario generarlos como periodos No Informados) pero no se incluyen en la columna ISI (porque no pueden ser generados por el PASO 2), y además, tampoco pueden ser generados en el PASO 1. Por suerte, nuestro Modelo de Versionado no permite versiones discontinuas, por lo que se trata de un caso que no puede darse, y que se presente en éste Artículo exclusivamente con fines didáctico (ojo, porque si este caso se pudiera dar, el algoritmo presentado en este capítulo sería incorrecto, ya que no está contemplado dicho caso, y se podrían producir resultados inesperados).
Confío haberme explicado de forma clara en este capítulo, pero en cualquier caso, la realidad es que se trata de un capítulo bastante árido y dificil de explicar, quizás porque pueda resultar algo abstracto.
Es muy recomendable la lectura de este capítulo, junto con el Gráfico de Línea de Tiempo que ya vimos en uno de los capítulos anteriores, de forma que podamos ver gráficamente los diferentes casos de versiones de la tabla Padre, y así resulte fácil comprobar y validar la eficacia de nuestras consultas.
También es importante realizar una aclaración a una duda común ¿Y si no deseamos las versiones con Padre desconocido? Pues muy fácil. En el primer paso realizamos un INNER JOIN en vez de un LEFT JOIN, y el segundo paso lo omitimos. Con esto, habremos omitido todas las versiones con Padre Desconocido o No Informado.
Sobre los campos Fecha Alta y Fecha Baja, aquí no nos afectan en absoluto, ya que en todo caso, los incluiremos en la nueva tabla denormalizada. Otra cosa, es que cuando se consulte la tabla denormalizada, se desee consultar considerando los valores de Fecha Alta y Fecha Baja, pero insisto, que estrictamente para la denormalización de tablas versionadas en el Modelo de Versionado utilizado en este artículo, no nos afecta en absoluto.
Y con esto finalizo este capítulo. Espero que pueda serviros, ya que esa ha sido mi intención, y tengo que admitir que ha costado mucho más tiempo del previsto la redacción, pruebas y revisión de este capítulo (bueno... y de todo este Artículo) de lo que en principio había estimado, así que al menos (y como siempre), espero que os sirva (en cualquier caso, sois unos benditos por haberlos leído entero... jeje ;-). |
|
|
| Miembros de |
|
 |
| Acerca de |
|
| Contigo desde Oct 2007 |
| 623 usuarios registrados |
| 86146 pageloads/mes |
| Ranking Alexa 498160 |
|
Archivo
|
|








