Por qué utilizar datos grandes – LOBs & BLOBs
Puede haber dos razones por la que tengamos que trabajar con datos grandes:
- Por que trabajemos con una aplicación que utilice estos tipos de datos (ej: Microsoft Sharepoint Portal Server).
- Por que desarrollemos nuestra propia aplicación y necesitemos almacenar ficheros o cantidades enormes de texto.
En el primero de estos casos, dependemos del tratamiento que la aplicación en cuestión realice con los datos grandes. Sin embargo, en el segundo caso, existen dos posibilidades a elegir para la gestión de estos datos, cada una con sus ventajas e inconvenientes:
- Almacenar los datos grandes (LOBs & BLOBs) en la propia base de datos. Tiene el inconveniente de que la base de datos puede multiplicar su tamaño (el factor multiplicador depende de cada caso particular), con un potencial impacto en el espacio necesario para la base de datos, y en los tiempos de copia de seguridad, restauración, y otras operaciones de mantenimiento. Por el contrario, al guardar todos los datos juntos (datos alfanuméricos y fechas, junto con los datos grandes o LOBs), se simplifica su manipulación (es más fácil que con el tiempo se mantengan sin incoherencias).
- Almacenar los datos grandes (LOBs & BLOBs) fuera de la base de datos, almacenando en la base de datos algún tipo de referencia (ej: una URL o una ruta UNC). La base de datos se suele volver mucho más manejable (esto depende de la cantidad de datos LOBs & BLOBs que sea en cada caso, claro), pero por el contrario, existe el problema de mantener la integridad de los mismos: sincronizar las copias de seguridad de la base de datos con las copias de seguridad de los ficheros externos es un problema, pero también hay que tener en cuenta que ciertas transacciones sobre la base de datos, deberán tener asociadas ciertas operaciones sobre el sistema de ficheros, y en este pequeño detalle nos podemos encontrar problemas imprevistos (alguna que otra horilla de más programando… ;-).
En este artículo, nos interesa centrarnos en el almacenamiento de los datos grandes (LOB) en la base de datos, en particular en Microsoft SQL Server.
Tipos de datos grandes – LOBs & BLOBs
Microsoft SQL Server 2000 soporta varios tipos de datos grandes LOBs & BLOBs, capaces de almacenar hasta 2GB.
- IMAGE. Permite almacenar datos binarios (BLOB), como pueden ser imágenes, ficheros de Microsoft Office, etc. También se puede utilizar para guardar datos binarios, tales como información vectorial en formato binario, etc.
- TEXT. Permite almacenar grandes cantidades de texto. Presenta algunas limitaciones (ej: no permite concatenaciones).
- NTEXT. Permite almacenar grandes cantidades de texto en formato UNICODE. Presenta algunas limitaciones (ej: no permite concatenaciones).
No es posible declarar variables de estos tipos de datos. Habitualmente los veremos en tablas, vistas, como parámetros de procedimientos almacenados… quizás en tablas temporales o en variables de tipo tabla… pero no como variables locales.
Hay que tener en cuenta que no suele ser recomendable almacenar 2GB en un campo de una tabla. Cuando se necesita guardar cantidades de información tan grandes, suele dividirse en varios campos (o filas), almacenando en cada uno de ellos una cantidad menor. Por ejemplo, en vez de guardar una imagen tan grande en un único campo, se dividiría la imagen en varios trozos, y cada trozo se guardaría en un campo o fila distinto. En caso contrario, el acceso a la base de datos podría llegar a ser bastante más lento.
Microsoft SQL Server 2005 también soporta los tipos IMAGE, TEXT y NTEXT, pero la documentación avisa que estos datos desaparecerán en futuras versiones. Para ello, aunque mantiene el soporte de dichos tipos de datos, incorpora los siguientes tipos de datos nuevos:
- VARBINARY(MAX). Sustituye al tipo IMAGE.
- VARCHAR(MAX). Sustituye al tipo TEXT, pero sin embargo, si soporta concatenaciones.
- NVARCHAR(MAX). Sustituye al tipo NTEXT, pero sin embargo, si soporta concatenaciones.
- XML. Es un tipo nuevo. Permite almacenar datos XML. Sin embargo, también podríamos almacenar datos XML en cualquier otro de los tipos de datos grandes de SQL Server, pero, sobre un dato de tipo XML se puede además crear índices XML, realizar consultas XML, etc. Este es el factor diferenciador entre un tipo XML y otro tipo LOB de SQL Server.
Importar y Exportar datos grandes (LOBs & BLOBs)
Existen varias formas de importar o exportar datos grandes (LOBs & BLOBs) con SQL Server. De hecho, existen distintos escenarios. Por ejemplo, al importar es posible que el origen sea un fichero de una imagen disponible en el propio sistema de archivos, o quizás, el origen sea otra base de datos (SQL Server o de otro Proveedor como ORACLE o DB2), en la que esté almacenado el dato. En cualquier caso, a continuación se comenta un resumen de distintas opciones posibles para este fin:
Es posible insertar valores literales desde una instrucción INSERT convencional. Esto que puede parecer trivial, no todos los motores de base de datos lo soportan (véase el caso de IBM INFORMIX, que se apoya en la utilización de funciones como FILETOBLOB y LOTOFILE). A continuación, se muestra un ejemplo:
INSERT INTO dbo.tbl_imagenes (id, imagen)
VALUES (2, 0x004F)
INSERT INTO tbl_texto (id, texto)
VALUES (1, 'Texto de ejemplo') |
Del mismo modo, es posible actualizar este tipo de datos utilizando instrucciones UPDATE convencionales.
Por el contrario, sobre datos TEXT, NTEXT o IMAGE, no será posible realizar operaciones más complejas directamente con instrucciones UPDATE (ej: concatenaciones). Para cubrir esta necesidad, es posible utilizar las funciones READTEXT, UPDATETEXT, WRITETEXT, PATINDEX, y DATALENGTH. Algunas de estas funciones requieren un puntero (un valor binario de 16 bytes de precisión) que puede obtenerse a su vez con la función TEXTPTR. A continuación se muestra un ejemplo:
-- *** Declarar el Puntero ***
DECLARE @puntero varbinary(16)
-- *** Obtener Puntero al dato deseado ***
SELECT @puntero = textptr(imagen)
FROM tbl_imagenes
WHERE id = 1
-- *** Acceder al dato deseado a través del puntero ***
READTEXT tbl_imagenes.imagen @puntero 12 4 |
Una de las ventajas que ofrecen estas funciones, es la posibilidad de acceder a "trozos" de un dato grande (LOB), con el fin de facilitar su manipulación incluso desde máquinas que no dispongan de grandes cantidades de memoria (en la época en que se concibieron estas funciones, no había muchas máquinas con 2GB de RAM).
Sin embargo, con el fin de simplificar el acceso a este tipo de datos, en SQL Server 2005 podemos seguir utilizando estos tipos, o bien, utilizar los nuevos tipos de datos VARCHAR(MAX), NVARCHAR(MAX) y VARBINARY(MAX). Con estos nuevos tipos, podemos trabajar como si fueran datos normales, y por supuesto, no es necesario utilizar punteros. Además, la recomendación de Microsoft es trabajar con los nuevos tipos de datos, debido a que en un futuro serán la única posibilidad (TEXT, NTEXT e IMAGE desaparecerán en futuras versiones de Microsoft SQL Server).
Es posible importar ficheros desde SQL Server 2005, utilizando OpenRowSet con la opción BULK (la opción BULK no está soportada en SQL Server 2000). A continuación se muestra un ejemplo para leer un fichero binario:
| SELECT * FROM OpenRowSet(BULK N'D:\temp\eiffel.jpg', Single_Blob) AS Imagen |
Una limitación importante, es que no se puede utilizar una variable para especificar el fichero que se desea leer. Como alternativa, se puede utilizar SQL Dinámico, como en el siguiente ejemplo:
DECLARE @fichero NVARCHAR(250)
SET @fichero = N'D:\temp\eiffel.jpg'
EXEC('SELECT * FROM OpenRowSet( Bulk N''' + @fichero + ''', Single_Blob) AS Imagen') |
Se debe recordar, que es muy imporante tener en cuenta el posible riesgo de ataques SQL Injection al utilizar código SQL Dinámico en nuestros sistemas y aplicaciones.
Los ejemplos aquí mostrados utilizan Single_Blob para cargar datos binarios, pero es también posible utilizar Single_Clob y Single_NClob para datos ASCII y UNICODE.
Es necesario que el inicio de sesión utilizado sea miembro de la función de servidor bulkadmin, o bien, disponer del derecho Administer BULK Operations.
Se podrían contar muchas más cosas relacionadas con OpenRowSet, pero esta introducción es suficiente para el alcance de este Artículo.
Esta utilidad de símbolo de sistema, permite principalmente exportar una tabla de SQL Server a un fichero, así como importar datos de un fichero a una tabla de SQL Server. Funciona tanto con SQL Server 2000 como con SQL Server 2005. A continuación se muestra un ejemplo de exportación:
| bcp Pruebas..tbl_imagenes out d:\temp\export.bin -S .\SQLExpress -T -n |
A continuación se muestra un ejemplo de importación, equivalente al ejemplo anterior:
| bcp Pruebas..tbl_imagenes in d:\temp\export.bin -S .\SQLExpress -T -n |
En estos ejemplos se importa y exporta una tabla completa, con todos sus campos, sean LOB o no. Es posible exportar el resultado de una consulta, con el fin de seleccionar que filas y columnas se desean exportar, utilizando la opción queryout en vez de la opción out.
Para exportar e importar datos en los ejemplos anteriores, BCP.EXE utiliza un formato de fichero propietario de tipo binario, y funciona estupendamente para mover datos entre distintas instancias de SQL Server. Sin embargo, BCP.EXE puede utilizar un formato de fichero de tipo carácter utilizando el parámetro –c, lo cual resulta útil para intercambiar datos entre SQL Server y otros sistemas. Además, entre los múltiples parámetros posibles, se puede indicar los caracteres deseados para terminador de fila y para terminador de columna.
Llegados a este punto, la pregunta del millón es ¿es posible importar una foto utilizando BCP.EXE? En el siguiente Artículo de Microsoft se muestra un ejemplo de cómo conseguir este objetivo:
INF: Using BCP to Import Image Data into SQL Server
Quizás su principal inconveniente, sea tener que conocer de antemano el tamaño del fichero, si no queremos obtener una excepción. Otra forma, sería utilizando un fichero de formato. Si por ejemplo, tenemos una tabla con un campo autonumérico y un campo IMAGE, podemos crearnos un archivo de formato que contenga la definición sólo del campo IMAGEN (sin la definición del campo autonumérico), especificando el tamaño del fichero que deseamos cargar. A continuación se muestra un ejemplo de un archivo de formato de este tipo:
8.0
1
1 SQLIMAGE 0 143298 "" 2 imagen "" |
Con un fichero de formato similar, ya sólo queda ejecutar un comando similar al siguiente:
| bcp Pruebas..tbl_imagenes in d:\temp\eiffel.jpg -S .\SQLExpress -T |
Otro truco que puede ser interesante es utilizar el procedimiento almacenado xp_cmdshel para a través de él, ejecutar un comando BCP.EXE. En la siguiente página, es posible encontrar un ejemplo:
Stored procedure: Export/import data using BCP
Para poder exportar con BCP.EXE sólo es necesario tener permiso de SELECT sobre la tabla, y del mismo modo, para poder importar con BCP.EXE sólo es necesario tener permiso de SELECT/INSERT sobre la tabla.
Se podrían contar muchas más cosas relacionadas con BCP.EXE, pero queda fuera del alcance de este Artículo.
Es similar al comando BCP.EXE con la opción IN. Sin embargo, mientras que BCP.EXE se ejecuta fuera del proceso de la instancia de SQL Server (out-of-process), o incluso en una máquina distinta de la que actúa de servidor de base de datos, una sentencia BULK INSERT es ejecutada por el propio motor de SQL Server (in-process). BULK INSERT suele ofrecer mejor rendimiento que BCP.EXE, y sólo permite importar datos a SQL Server.
Suele utilizarse junto con un fichero de formato, como se muestra en el siguiente ejemplo, o bien, especificando manualmente la configuración del fichero de entrada (terminador de fila, terminador de columna, etc.). Una ventaja de utilizar un fichero de formato, es que se puede crear automáticamente si utilizamos BCP con la opción out (para exportar).
BULK INSERT Pruebas..tbl_imagenes from 'd:\temp\prueba.bin'
WITH (FORMATFILE='D:\temp\bcp.fmt'); |
Si en lugar de cargar una tabla con un fichero (por ejemplo obtenido de una exportación realizada con BCP.EXE), deseamos cargar una imagen (o un documento de office, etc.) en un campo de una tabla, al igual que se comentó anteriormente con el comando BCP.EXE, se podría utilizar un fichero de formato que contenga la definición sólo del campo IMAGEN (sin la definición del resto de campos de la tabla), especificando el tamaño del fichero que deseamos cargar. A continuación se muestra un ejemplo de un archivo de formato de este tipo:
8.0
1
1 SQLIMAGE 0 143298 "" 2 imagen "" |
Con un fichero de formato similar, ya sólo queda ejecutar una sentencia BULK INSERT similar al siguiente:
BULK INSERT tbl_imagenes
FROM 'd:\temp\eiffel.jpg'
WITH (formatfile='c:\upload\bcp.fmt') |
Es necesario que el inicio de sesión utilizado sea miembro de la función de servidor bulkadmin, o bien, disponer del derecho Administer BULK Operations. Así mismo, el usuario de base de datos debe tener permiso de INSERT sobre la tabla en la que se desea insertar.
La utilidad BII.EXE, disponible en el Kit de Recursos de SQL Server 2000 (descargable para suscriptores de MSDN junto con su código fuente), es similar a la utilidad BCP.EXE. Sin embargo, cuando el campo de destino es de tipo IMAGE, y el fichero de origen contiene el nombre de un fichero precedido por un símbolo de arroba (ej: @d:\temp\imagen.jpg), es capaz de leer dicho fichero para insertarlo en la tabla de destino en vez de insertar el texto.
Es decir, lo que nos permite la utilidad BII.EXE es cargar un fichero de datos donde para los campos IMAGE en vez de venir la propia imagen, vienen una referencia al fichero que la contiene.
La principal limitación, ya la adelanta su nombre: sólo sirve para importar.
A continuación, se muestra un ejemplo de cómo se utilizaría BII.EXE:
| bii tbl_imagenes in d:\temp\prueba.txt /Slocalhost /DPruebas /Usa /PP@ssw0rd /t, /v |
Hemos probado con éxito a ejecutar BII.EXE en una máquina con sólo SQL Server 2000, conectándose a una máquina con sólo SQL Server 2005. También se ha probado a copiar BII.EXE a una máquina con sólo SQL Server 2005, y se ha ejecutado con éxito.
Aplicación de símbolo de sistema, disponible sólo con SQL Server 2000 y que utiliza DBLib. Hemos probado con éxito a ejecutar TEXTCOPY.EXE en una máquina con sólo SQL Server 2000, conectándose a una máquina con sólo SQL Server 2005. También se ha probado a copiar TEXTCOPY.EXE a la máquina SQL Server 2005 para poder ejecutarlo directamente desde una máquina SQL Server 2005, pero para conseguir que funcione, es necesario copiar también la librería ntwdblib.dll.
Es posible utilizar TEXTCOPY.EXE sin especificar ningún parámetro, en cuyo caso se comportará de forma interactiva. Por el contrario, si especificamos todos los parámetros necesarios y con los valores correctos, será capaz de ejecutarse sin solicitar ninguna información adicional. Una gran ventaja es que permite tanto importar como exportar datos grandes, TEXT o IMAGE. Otra cualidad importante, es que se necesita invocar una vez a esta utilidad para cada fichero que se desea importar o exportar (ej: si tenemos una tabla con 1300 filas, necesitaremos ejecutar TEXTCOPY.EXE 1300 veces con los parámetros apropiados en cada llamada). Otro detalle de esta utilidad es que no es capaz de insertar, es decir, al importar un fichero es necesario que la fila ya exista en SQL Server de tal modo que TEXTCOPY.EXE se limitará a actualizar el valor de la columna LOB especificada. Por esta razón, tanto al importar como al exportar, es necesario especificar la cláusula WHERE como parámetro. Otro detalle, es que al importar un fichero debe existir la fila y además el campo LOB debe estar relleno con cualquier valor. Si no está relleno, es decir, si contiene NULL, obtendremos el siguiente error al intentar importar:
ERROR: Text or image pointer and timestamp retrieval failed
Aunque no existe información disponible sobre esta utilidad en los Libros en Pantalla (BOL) de SQL Server 2000, puede ejecutarse textcopy.exe /? para obtener información de ayuda.
Al igual que comentamos con el comando BCP.EXE, puede ser interesante utilizar esta utilidad junto con el procedimiento almacenado xp_cmdshell, para así poder invocarlo desde dentro del motor de base de datos.
Para poder exportar con TEXTCOPY.EXE sólo es necesario tener permiso de SELECT sobre la tabla, y del mismo modo, para poder importar con BCP.EXE sólo es necesario tener permiso de SELECT/INSERT sobre la tabla.
Es posible utilizar servidores vinculados para importar datos, de otras instancias SQL Server, así como de otros proveedores (ej: ORACLE, IBM DB2, etc). Es muy importante tener en consideración que el proveedor utilizado es vinculante, es decir, si deseamos mover datos binarios grandes a través de un Servidor Vinculado que no es SQL Server, el proveedor utilizado deberá soportar mover este tipo de datos.
A traves de un paquete DTSX, es posible utilizar una tarea de Flujo de Datos (Data Flow), para definir un origen, un destino, y una carga/transformación de datos. Sin embargo, si deseamos mover datos binarios grandes a través de SSIS, los proveedores utilizados deberán soportar mover este tipo de datos.
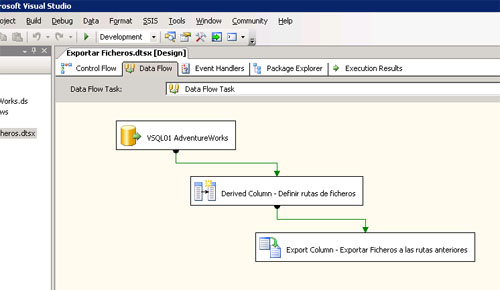
Una alternativa, es exportar los datos grandes (LOBs o BLOBs) a ficheros (ej: guardar imágenes almacenadas en la base de datos, en el sistema de ficheros). Para ello, podemos utilizar una tarea de tipo Data Flow, y en ella, utilizar como Origen de Datos una conexión (ej: conexión OLE DB a SQL Server) a una tabla que almacena imágenes, y como destino una tarea Export Column en la que tenemos que decir qué columnas contienen los datos grandes (LOBs o BLOBs) y qué columna contiene los nombres de los ficheros deseados para exportar. Es posible utilizar una tarea intermedia del tipo Derived Column, en la que utilizar alguna fórmula con la que construir las rutas completas de los ficheros (ej: "D:\\TEMP\\" + NombreFichero), para luego usarlas en la tarea Export Column. A continuación se muestra una imagen con el contenido del Data Flow.
También es posible importar ficheros externos (ej: imágenes) a un flujo de datos (ej: importar imágenes desde el sistema de ficheros). Esto es muy útil en ocasiones, como cuando desde un motor de base de datos exportan a un fichero los datos alfanuméricos, y en ficheros separados los datos correspondientes a los campos grandes (LOBs o BLOBs) como imágenes. Para esto, es necesario disponer en un Data Flow, de un Origen de Datos en el que se especifique la ruta completa de los ficheros que se desean importar (sino, será necesario agregar una tarea de tipo Derived Column, para incluir alguna fórmula capaz de especificar la ruta completa de cada fichero origen), incluir también una tarea de tipo Import Column, y finalmente un destino de datos.
Para configurar la tarea Import Colum, en la pestaña Import Columns seleccionar la columna que contiene la ruta completa a los ficheros externos que se desean importar, con la opción Usage Type a Read Only. Seguidamente, en la pestaña Input and Output Properties, añadir una nueva columna de salida que contendrá el fichero externo (click Add Column). Tomar el valor de la propiedad ID de esta nueva columna de salida, y a continuación, establecer el valor de la propiedad FileDataColumnID de la columa de entrada al valor de la propiedad ID de la nueva columna de salida. Con esto, habremos incluido en nuestro Data Flow los datos de ficheros externos, con el fin de importar dicha información en los destinos de datos que se desee.
La API de ADO, es la forma típica de acceder a bases de datos desde aplicaciones VB6 y ASP. Habitualmente, se trabaja con ADO creando un objeto conexión (ADODB.Connection), y sobre este, se ejecuta una consulta cuyo resultado se recibe sobre un objeto de conjuntos de registros (ADODB.Recordset), que posteriormente se recorre a través de un bucle. Así mismo, también se pueden ejecutar consultas DML como INSERT o UPDATE, que no devuelven conjuntos de registros.
How To Open ADO Connection and Recordset Objets
También se utiliza el objeto comando (ADODB.Command) tanto para ejecutar sentencias SQL, como para invocar a procedimientos almacenados.
Sin embargo, para acceder a datos grandes a través de ADO suele utilizarse el objeto ADODB.Stream. Este objeto proporciona métodos como SaveToFile y LoadFromFile, que junto con la colección Fields, permito cubrir nuestro objetivo. El siguiente Artículo de la Web de Soporte de Microsoft, muestra un par de ejemplos.
How To Access and Modify SQL Server BLOB Data by Using the ADO Stream Object
ADODB.Stream fué introducido con ADO 2.5, para simplificar el acceso a datos grandes, que en versiones anteriores se realizaba a través de los métodos GetChunk y AppendChunk del objeto Field.
En cualquier caso, también puede accederse a campo grande directamente, sin utilizar ADODB.Stream, GetChunk ni AppendChunk. A continuación se muestra un ejemplo de una página ASP muy útil, cuyo único fin es obtener una imagen de una base de datos SQL Server, apoyándose en el comando Response.BinaryWrite y en la utilización de Microsoft ADO. En este caso, se accede a la imagen directamente a través de la colección Fields, sin utilizar ADODB.Stream ni GetChunk. El código es el siguiente:
<%
Response.ContentType = "image/gif"
Set cn = Server.CreateObject("ADODB.Connection")
cn.Open "Provider=SQLOLEDB; Data Source=VSQL02; Initial Catalog=Pruebas; User ID=sa; Password=*****"
Set rs = cn.Execute("SELECT imagen FROM tbl_imagenes WHERE id=2")
Response.BinaryWrite rs("imagen")
Response.End
rs.Close
Set rs = Nothing
cn.Close
Set cn = Nothing
%>
|
Así, una vez que hemos escrito esta página y la hemos publicado en un servidor IIS (y modificado con los datos de conexión adecuados, etc.), podemos invocarla directamente desde una navegador (ej: http://localhost/TestApp/imagen.asp) obteniendo la correspondiente imagen. También, podemos invocarla desde otra página (aunque no sea ASP, o aunque no esté en la misma máquina), por ejemplo desde un TAG de tipo img en una página HTML, como en el siguiente ejemplo:
<html>
<head>
<title>Página de ejemplo</title>
</head>
<body>
<img src="./imagen.asp" border=0>
</body>
</html>
|
La API de ADO.Net, es la forma típica de acceder a bases de datos desde aplicaciones realizadas con el Microsoft Framework, ya sea Windows Forms, Web Forms, XML Web Services, o cualquier otro tipo. Puede verse como la evolución natural de ADO.
En ADO.Net se ha diferenciado muy claramente dos maneras de trabajar con bases de datos:
- Trabajar NO orientado a la conexión.
Se está habitualmente desconectado de la base de datos. Cuando es necesario manipular datos, la aplicación se conecta a la base de datos, realiza la manipulación de datos, y se desconecta. Aprovecha del uso de Pooles de Conexiones para minimizar el coste de conectarse y desconectarse continuamente. Utiliza objeto DataSet, en los que almacena los datos obtenidos de la base de datos, siendo posible trabajar sobre el DataSet, y posteriormente actualizar la base de datos conforme a los datos contenidos en el DataSet.
- Trabajar orienado a la conexión.
Se está conectado a la base de datos de manera continua.










