Continuando con nuestra serie de artículos de Problemas de Rendimiento en SQL Server relacionados con los eventos de traza Hash Warning y Sort Warnings, en esta segunda entrega vamos a tratar el tema de los Operadores Costosos (Expensive Operators) de los Planes de Ejecución y la asignación de Memoria de Consulta (Query Grants) para consultas SQL que incluyen estos Operadores Costosos, así como sus implicaciones de Rendimiento en entorno con múltiples CPUs (MDOP).
Planes de Ejecución y Operadores Costosos (Expensive Operators) en SQL Server
Como sabemos, el comportamiento general de SQL Server al ejecutar un procedimiento almacenado o una consulta SQL, implica que en la primera ejecución se genera el Plan de Ejecución de la consulta o procedimiento almacenado a ejecutar, en un proceso denominado Compilación, tras lo cual, dicho Plan de Ejecución será cacheado (almacenado en memoria RAM, en una zona de memoria específica para ello, denominada PROC CACHE). De este modo, la próxima vez que volvamos a ejecutar esa misma consulta SQL o procedimiento almacenado, no será necesario volver a generar el Plan de Ejecución, con vistas a optimizar así la utilización de los recursos de SQL Server. Evidentemente, bajo ciertas circunstancias un Plan de Ejecución puede volverse inválido, de tal modo que en una próxima ejecución necesite volver a compilarse (ej: cambios en las tablas o índices utilizados por el Plan de Ejecución, actualizaciones de las estadísticas, etc.).
Antes de seguir, aclarar que en SQL Server:
- Existe una zona de memoria denominada Buffer Pool, la cual almacena en memoria RAM una copia de las páginas de datos de los ficheros de nuestras bases de datos, para minimizar el acceso a disco, y así, mejorar el rendimiento. Por darle un punto de vista práctico, en ocasiones para realizar Tunning de consultas, es útil utilizar el comando DBCC DROPCLEANBUFFERS para vaciar el Buffer Pool y probar nuestras consultas en igualdad de condiciones (es decir, evitar que una consulta parezca más rápida porque encuentra todas las páginas en Caché, en lugar de por ser una consulta realmente más óptima). La recomendación es ejecutar un CHECKPOINT y posteriormente ejecutar el DBCC DROPCLEANBUFFERS.
- Existe otra zona de memoria denominada PROC CACHE, la cual almacena los Planes de Ejecución utilizados por SQL Server, con el objetivo de poder reutilizarlos. Ya hemos tocado ligeramente este tema alguna vez, como por ejemplo, para reducir TEMPDB utilizando el comando DBCC FREEPROCCACHE.
- Existe otra zona de memoria denominada Query Memory o Workspace Memory, la cual es utilizada para asignar memoria a las consultas SQL que necesitan ejecutarse, con el objetivo de utilizarla para almacenar datos temporales, típicamente para ordenaciones y uniones de filas. Por defecto, el tamaño total de la Query Memory o Workspace Memory de una instancia de SQL Server es el 75% de la memoria RAM de dicha instancia (ej: si asignamos 8GB de RAM a una instancia de SQL Server, la Query Memory será de unos 6GB). Por verlo en un ejemplo, si una consulta compleja es ejecutada por SQL Server, almacenará su Plan de Ejecución en la PROC CACHE, las páginas de tablas e índices se almacenarán en el Buffer Pool, y la memoria necesaria para ejecutarse (ej: para realizar ordenaciones) se tomará de la Query Memory o Workspace Memory.
Continuamos.
El Plan de Ejecución de una consulta o procedimiento almacenado, indica a SQL Server cómo debe procesar dicha consulta o procedimiento almacenado, especificando detalles cómo qué índices se deben utilizar, cómo se debe acceder a dichos índices (ej: INDEX SEEK o INDEX SCAN), utilizar o no paralelismo (múltiples procesadores), cuanta memoria RAM es necesaria para la ejecución, que algoritmos utilizar para mezclar diferentes conjuntos de resultados, etc.
Básicamente, podemos entender un Plan de Ejecución como un conjunto de Operaciones, las cuales son ejecutadas en cierto orden por el motor de SQL Server para obtener el resultado de la consulta o procedimiento almacenado que se desea ejecutar. Algunas de estas Operaciones se conocen como Operaciones Costosas (Expensive Operators), pues implican un consumo de recursos mucho más elevado que el resto de Operaciones que podemos encontrar en un Plan de Ejecución, especialmente en lo relacionado a necesidades de memoria (en concreto, de Query Memory o Workspace Memory). En particular, estamos hablando de Operadores como:
- SORT.
- SORT DISTINCT.
- HASH JOIN.
- HASH AGGREGATE.
El hecho de que las necesidades de memoria RAM de una consulta o procedimiento almacenado son estimadas y cacheadas en tiempo de compilación y utilizadas en tiempo de ejecución (reutilizando el Plan de Ejecución en cache), pueden producir un comportamiento poco deseado. A esto hay que sumarle otros detalles, como por ejemplo, que en función del número de CPUs utilizados para ejecutar una consulta, las necesidades de memoria (Query Memory) de la misma variarán: A mayor número de CPUs, más memoria (Query Memory) necesitará la consulta (esto lo veremos en mayor detalle más adelante en este mismo artículo). Otro detalle a tener en cuenta, es que si una consulta que va a ser ejecutada, no puede disponer de la memoria RAM que le ha sido asignada, se quedará en Espera (Wait). Otro caso, es que a dicha consulta se le asigne una cantidad de memoria RAM menor de la recomendable (ej: porque la instancia de SQL Server tiene poco RAM), en cuyo caso, si dispone de dicha memoria RAM la consulta empezará a ejecutarse, pero evidentemente, con el coste de escribir en TEMPDB (spilling to TEMPDB) y realizar el mismo trabajo en múltiples pasos.
Existen muchos más detalles internos del funcionamiento de la concesión de memoria de consulta (Memory Grant). A continuación se muestran varios ejemplos del funcionamiento por defecto de los Memory Grants y de la gestión de la Query Memory o Workspace Memory:
- El 5% de la Query Memory o Workspace Memory está reservada para la ejecución de consultas pequeñas.
- Ninguna consulta puede consumir más del 20% de la Query Memory o Workspace Memory.
- Existen 5 colas para la asignación de memoria (Query Memory) a las consultas.
- Toda petición de memoria (Query Memory) debe pasar por estas colas, que son despachadas en formato FIFO.
Esto implica que si tenemos múltiples consultas simultáneas que requieran de una asignación de memoria de consulta (Query Memory o Workspace Memory), podría ocurrir que alguna consulta tuviese que esperar (Wait) encolada (pendiente de que le sea asignada la memoria que necesita), pudiendo incluso llegar a producirse un Timeout.
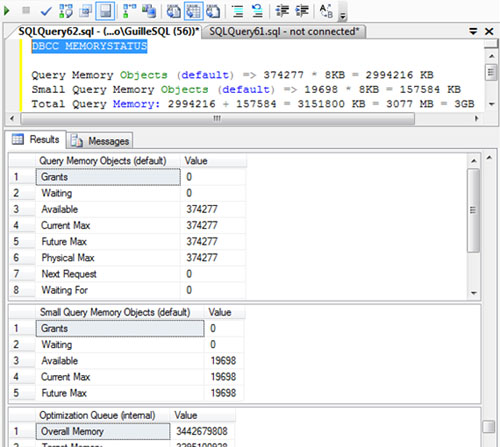
Pero ¿Cómo podemos comprobar cuanta memoria RAM tenemos asignada para memoria de consulta (Query Memory o WorkSpace Memory)? Una de las posibles formas es utilizar el comando DBCC MEMORYSTATUS, que queda descrito en la KB907877 de Microsoft: How to use the DBCC MEMORYSTATUS command to monitor memory usage on SQL Server 2005
La salida del comando DBCC MEMORYSTATUS es bastante extensa, ya que contiene una gran cantidad de conjuntos de resultados (result sets). A continuación se formula cómo conocer los valores del total de Memoria de Consulta, así como la Memoria de Consulta destinada a consultas pequeñas y al resto de consultas:
- Memoria de Consulta destinada para consultas pequeñas. Lo obtenemos de los valores de Query Memory Objects (default), teniendo en cuenta que está expresado como un número de páginas, cada una de 8KB.
- Memoria de Consulta destinada para el resto de consultas. Lo obtenemos de los valores de Small Query Memory Objects (default), teniendo en cuenta que está expresado como un número de páginas, cada una de 8KB.
- Total de Memoria de Consulta. Es la suma de los dos valores anteriores.
En la siguiente pantalla capturada se muestra un ejemplo realizado sobre una máquina con SQL Server 2008 R2 configurado con 4GB para el SQL, de los cuales, 3GB están dedicados a Memoria de Consulta (Query Memory o WorkSpace Memory).
A continuación, vamos a empezar a ver algunas de estas cosas, de una forma un poco más práctica, utilizando ejemplos.
Descripción del Escenario de Pruebas
Para la redacción del presente artículo, hemos utilizado un SQL Server 2008 R2 Developer x64 corriendo sobre Windows 7 SP1 Ultimate x64 en un Intel Core i7 con 8GB de RAM y 8 Cores. Sobre esta instalación, hemos montado las Bases de Datos de ejemplo de Adventure Works.
Vamos a utilizar la tabla SalesOrderDetail de la base de datos AdventureWorks. Sobre esta tabla, hemos creado un índice No Agrupado, conforme a la siguiente sentencia DDL.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID
ON [Sales].[SalesOrderDetail] ([ModifiedDate])
INCLUDE ([SalesOrderID],[SalesOrderDetailID])
GO
|
Sobre este entorno, vamos explicar en primer lugar el concepto de Operadores Costosos (Expensive Operators) de los Planes de Ejecución de SQL Server, para seguidamente entender el comportamiento de estas operaciones (introduciremos el concepto de Memory Grant), y así poder entender la problemática de los Eventos de Traza Hash Warning/Sort Warning y su relación con el cacheo de planes de ejecución, operadores costosos, el Memory Grant, y el acceso a TEMPDB por desbordamiento (spilling to TEMPDB).
Antes de la ejecución de las consultas descritas en este artículo, hemos ejecutado un par de opciones SET (STATISTICS IO y STATISTICS TIME), con el objetivo de obtener información estadística adicional sobre las instrucciones a ejecutar. Esto nos permite obtener cierta información bastante útil, como por ejemplo, conocer si ha sido necesaria la creación de WorkTables durante la ejecución. En particular, hemos activado las siguientes opciones SET.
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
|
Adicionalmente, vamos a ejecutar una Traza para capturar los Eventos Hash Warning/Sort Warning, y así tener conocimiento de cuando se producen. Al margen, es una buena práctica crear trazas personalizadas para capturar estos Eventos en nuestros entornos de Producción, y tener un histórico de los mismos.
Los ejemplos que vamos a realizar en el presente artículo, están inspirados en el Post Inside Hash and Sort Warnings, del Blog de Margarita Naumova (TecnNet).
Memory Grant: Consideraciones de ejecución y memoria de los Operadores Costosos (Expensive Operators)
En tiempo de compilación, al crear el Plan de Ejecución, en función del número estimado de filas que serán procesadas por los Operadores Costosos que estemos utilizando (SORT, SORT DISTINCT, HASH JOIN, HASH AGGREGATE, etc.), el Procesador de Consultas (QP - Query Proccessor) de SQL Server calculará el número de páginas de memoria necesarias para su ejecución. Este dato, lo podremos ver en el Plan de Ejecución etiquetado como Memory Grant.
Como comentamos, es importante tener en cuenta que las necesidades de memoria (Memory Grant) de una consulta dependerán de la opción de paralelismo con la que se ejecute.
Para verlo, vamos a ejecutar la siguiente consulta SQL sobre la base de datos de AdventureWorks, con la opción Include Actual Execution Plan habilitada (muy importante, ya que en el Plan de Ejecución Estimado no veremos el Memory Grant). Utilizaremos la cláusula ORDER BY para forzar que el Plan de Ejecución generado incluya el Operador Costoso (Expensive Operator) SORT. Téngase en cuenta, que para este ejemplo estamos forzando la utilización de una única CPU. Además, se trata de una consulta SQL estática, es decir, no estamos ejecutando ni un Procedimiento Almacenado ni una consulta SQL parametrizada.
SELECT so.SalesOrderID, so.ModifiedDate
FROM Sales.SalesOrderDetail so
WHERE so.ModifiedDate BETWEEN '20010701' and '20020201'
ORDER BY so.SalesOrderDetailID
OPTION (MAXDOP 1)
|
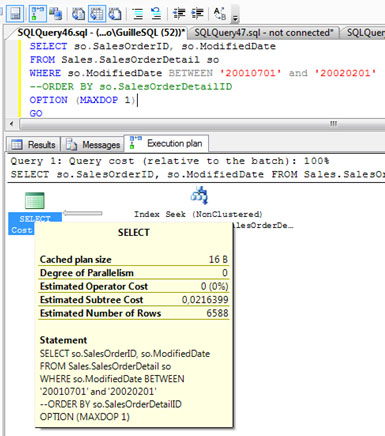
Si nos fijamos en el Plan de Ejecución, en la cajita correspondiente a la SELECT, podemos ver varios datos, entre los cuales está el valor de Memory Grant para la consulta que estamos ejecutando. En nuestro caso, un valor de Memory Grant de 1344. Creo que este valor se refiere a KB, aunque también he leído en algún otro Blog que se refiere a páginas de 8KB (lo que implicaría unos 10MB de RAM). El SORT afecta a 6588 filas de 23 Bytes, que suman unos 150KB, por lo que quiero pensar que el Memory Grant son 1344KB.
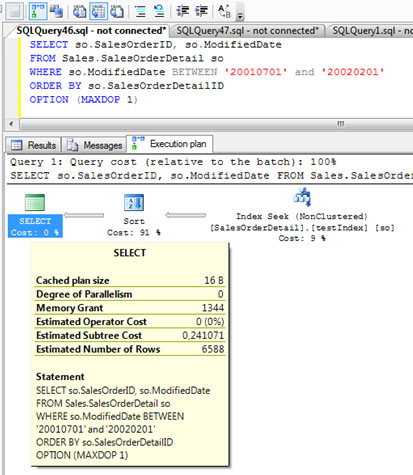
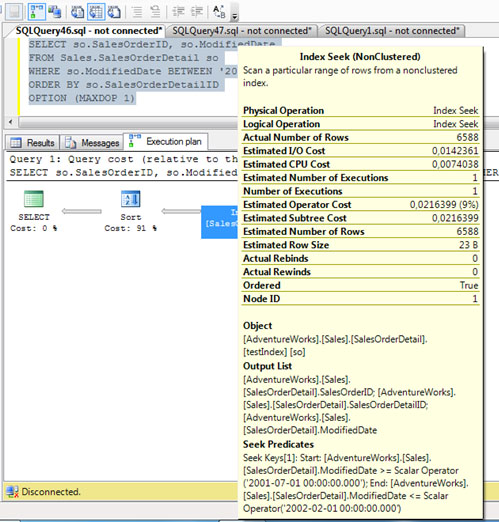
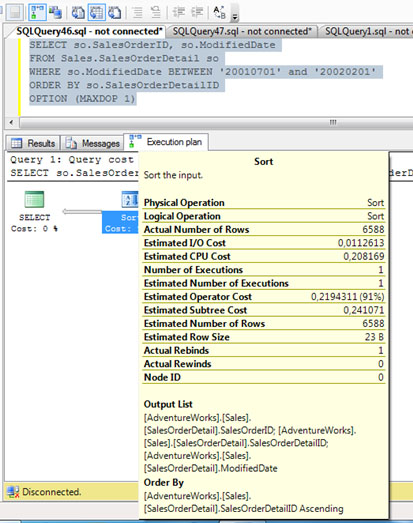
Por culturilla, aprovechamos para mostrar las propiedades del resto de cajitas del Plan de Ejecución de nuestra consulta SQL de ejemplo, empezando por la cajita correspondiente a la operación SORT (una operación costosa), que se muestran en la siguiente pantalla capturada. Muy importante, fijarse en que el número de filas estimadas y el número de filas afectadas (Estimated Number of Rows VS Actual Number of Rows) sea el mismo valor (o lo más cercano posible). Téngase en cuenta, que en función del número de filas estimadas, se estima la memoria RAM necesaria, por lo tanto, si se estimó un número de filas muy diferente al número de filas afectadas, podríamos estar sobrestimando o subestimando las necesidades reales de memoria RAM, y en consecuencia, incurriendo en problemas de rendimiento (spilling toTEMPDB, eventos Hash Warning y/o Sort Warnings, etc.).
A continuación se muestran las propiedades de la cajita correspondiente al INDEX SEEK del Plan de Ejecución de nuestra Consulta SQL de ejemplo.
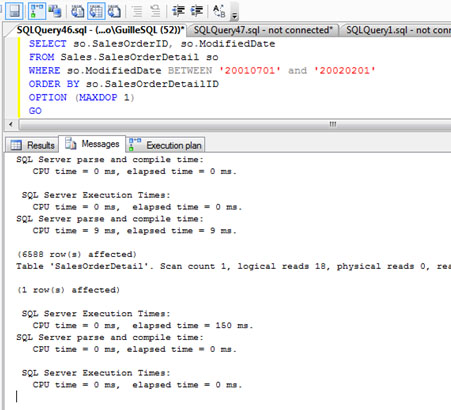
Como previamente activamos las opciones SET de STATISTICS IO y STATISTICS TIME, vamos a fijarnos en la salida de Messages, dónde podremos ver diversa información, cómo por ejemplo si se han utilizado WorkTables (en nuestro caso de ejemplo, no ha sido necesario utilizar WorkTables). Por lo tanto, la consulta se ha ejecutado íntegramente en memoria RAM, como Dios manda.
De momento, va todo bien. Tan sólo es la primera ejecución, y además, se trata de una Consulta SQL estática. No se han utilizado WorkTables, y evidentemente, no hay Eventos de Traza de tipo Hash Warning ni Sort Warning, como podemos ver en la siguiente pantalla capturada. Ojo, que deberemos tener clara la diferencia entre el acceso a TEMPDB por desbordamiento (spilling to TEMPDB) y por la utilización de Tablas de Trabajo (Work Tables), ya que no tienen nada que ver, y pueden dar lugar a confusión.
Es importante tener claro, que la Operación SORT es debida a que estamos utilizando la cláusula ORDER BY en nuestra Consulta SQL de ejemplo. Una mala práctica, quiero decir, como desarrolladores deberemos minimizar al máximo la utilización de ORDER BY, y en la medida de lo posible, evaluar delegar las ordenaciones a la Aplicación (es decir, prescindir de los ORDER BY en SQL Server, y ordenar en nuestras Aplicaciones). De hecho, en algunos entornos críticos de desarrollo, los Equipos de Calidad, buscan los ORDER BY, GROUP BY, y otras malas prácticas de las Consultas SQL, deteniendo su paso a Explotación si no se cumple con la normativa de Calidad de la organización.
A continuación, se muestra el Plan de Ejecución de la Consulta SQL de ejemplo, omitiendo la cláusula ORDER BY, obteniendo el siguiente Plan de Ejecución, sin operación SORT y sin Memory Grant.
Volviendo al tema de la relación entre los Memory Grant y las opciones de paralelismo de la consulta (DOP: Degree Of Parallelism), como comentábamos antes, para ejecutar una misma consulta SQL, la cantidad de memoria (Memory Grant) será mayor cuanto mayor sea el número de CPUs utilizado. Un detalle importante, ya que esto puede provocarnos algunos problemas de rendimiento adicionales. De hecho, ya hace un tiempo que hablamos sobre Configurar MDOP y sus consecuencias de Rendimiento en SQL Server.
Esto implica que si tenemos un SQL Server con múltiples CPU, en función del uso que hagamos de SQL Server, podría interesarnos limitar el número de CPUs que puede llegar a utilizar una consulta, ya sea a nivel de instancia (con sp_configure) o con sugerencias de consulta (MAXDOP). Recordemos, que al crear el Plan de Ejecución, SQL Server decide el número de CPUs a utilizar para ejecutar la consulta, además de las necesidades de memoria (Memory Grant).
Para verlo con nuestros propios ojos, podemos ejecutar la siguiente consulta (similar a la anterior), utilizando la sugerencia de consulta MAXDOP con diferentes valores, y comprobar los diferentes resultados de Memory Grant en función de las opciones de paralelismo utilizadas.
SELECT so.SalesOrderID, so.ModifiedDate
FROM Sales.SalesOrderDetail so
WHERE so.ModifiedDate BETWEEN '19000101' and '20120201'
ORDER BY so.SalesOrderDetailID
OPTION (MAXDOP 1)
|
A continuación se muestra los valores de Memory Grant obtenidos para diferentes valores de paralelismo:
- Para DOP = 1, obtenemos un Memory Grant de 9872
- Para DOP = 2, obtenemos un Memory Grant de 10384
- Para DOP = 4, obtenemos un Memory Grant de 11424
- Para DOP = 8, obtenemos un Memory Grant de 13504
No podía faltar el Script SQL con los ejemplos utilizados en este artículo. Téngase en cuenta, que para su ejecución es necesario haber instalado previamente las bases de datos de ejemplo de Adventure Works.
En próximos artículos, aprovecharemos para mostrar un ejemplo práctico de Sort Warnings por reutilización del Plan de Ejecución, un ejemplo práctico de Hash Warnings en SQL Server, y un ejemplo práctico de Sort Warning por estadísticas incorrectas o poco actualizadas.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.