Quizás se pueda pensar, que después del anterior artículo, Sort Warnings y TEMPDB: Ejemplo práctico, el presente artículo pueda no tener mucho sentido, ya que a simple vista parece que va a ser más de lo mismo: pues NO. Son casos distintos.
En el anterior artículo vimos como en el caso del Operador SORT, al reutilizar el Plan de Ejecución (CacheHit), podíamos incurrir en subestimación de memoria de consulta (generándose el evento Sort Warning y generando actividad adicional en TEMPDB), así como también incurrir en sobrestimación de memoria de consulta (desperdiciando memoria, lo cual, puede generar otros efectos secundarios adicionales).
Sin embargo, en el caso del presente artículo (operaciones Hash), vamos a ver algunos detalles específicos, que no vimos en el anterior caso del SORT, lo cual, me parece didácticamente muy interesante para comprender algunos de los Problemas de Rendimiento en SQL Server con los que nos puede tocar lidiar cuando estamos sufriendo eventos Hash Warning y Sort Warning. Principalmente, vamos a observar que el Operador utilizado en nuestro Plan de Ejecución puede variar en función de los parámetros de entrada. Tela. Es decir, además de que una consulta pueda ejecutarse en unas condiciones de subestimación o sobrestimación de memoria, nos encontramos que podríamos estar utilizando un Plan de Ejecución con Operadores no óptimos, al estar reutilizando el Plan de Ejecución (CacheHit). Esto no ocurría en el ejemplo del anterior artículo.
Antes de continuar, es importante tener claro los conceptos relacionados con el tema que estamos tratando, por lo que puede ser recomendable leer previamente los anteriores artículos, tanto el de Hash Warning y Sort Warnings como el de Sort Warning, Hash Warnings y Memory Grants en SQL Server. También es interesante leer previamente el artículo TEMPDB, acceso por desbordamiento (spilling) y Tablas de Trabajo (Work Tables). Estas lecturas previas nos serán de gran utilidad para tener algunos detalles frescos, que el temita se las trae (al menos yo sufro de memoria de pez, confío que mis hijos tarden en buscarme residencia ;-)
Preparando el entorno de Laboratorio
Partimos de una instancia SQL Server 2008 R2, con la base de datos de Adventure Works instalada. Para nuestro ejemplo, hemos creado un índice sobre la tabla que deseamos consultar, que eliminaremos al finalizar nuestras pruebas. Seguidamente hemos creado un procedimiento almacenado (dbo.SalesOrderSelectHash), el cual devuelve un conjunto de filas realizando un INNER JOIN entre dos tablas, filtrando por un rango de fechas (BETWEEN) que se especifican como parámetros de entrada de dicho Procedimiento Almacenado. Como en otras ocasiones, al final del artículo podéis descargar el Script SQL con todo el código de ejemplo.
Para continuar, deberemos abrir el SQL Profiler, y ejecutar una traza para capturar las ocurrencias de los siguientes Eventos:
- Errors and Warnings - Hash Warning
- Errors and Warnings - Sort Warnings
- Stored Procedures – SP:CacheHit
- Stored Procedures – SP:CacheInsert
Reducimos TEMPDB al menor tamaño posible. En nuestro caso de ejemplo, el MDF de TEMPDB ocupa tan sólo 1,5MB.
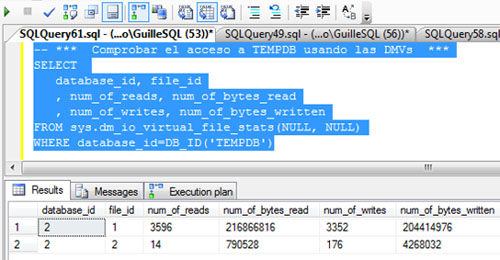
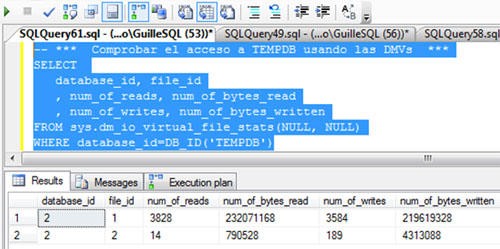
Además, vamos a consultar la DMV sys.dm_io_virtual_file_stats, para identificar las lecturas y escrituras realizadas sobre TEMPDB, y de este modo, poder tener otra medida que nos indique si se ha incurrido en un acceso a TEMPDB o no. En la siguiente pantalla capturada se muestra la consulta realizada y la salida obtenida.
Ejecución de las Pruebas para reproducir el evento Hash Warning
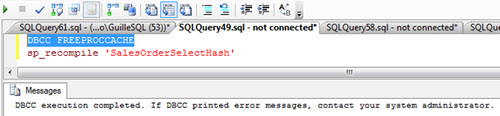
IMPORTANTE: para conseguir reproducir la reutilización del Plan de Ejecución es importante realizar las diferentes invocaciones al procedimiento almacenado, lo más seguidas posibles. Del mismo modo, pare reproducir la generación de un nuevo Plan de Ejecución, podemos esperar unos minutos antes de volver a invocar al procedimiento almacenado, utilizar el procedimiento almacenado del sistema sp_recompile, o ejecutar el comando DBCC FREEPROCCACHE para vaciar toda la caché de procedimientos de almacenados. Si no lo hacemos así, no conseguiremos reproducir los pasos descritos en este artículo. Continuamos.
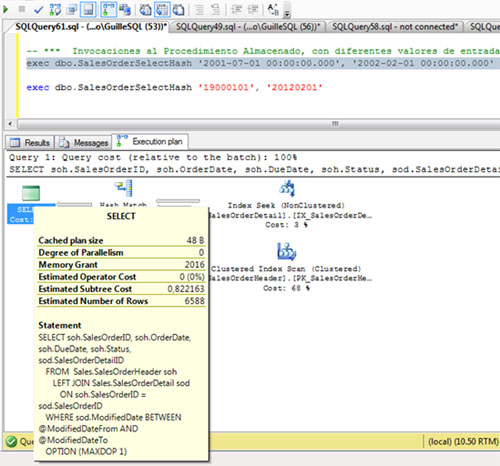
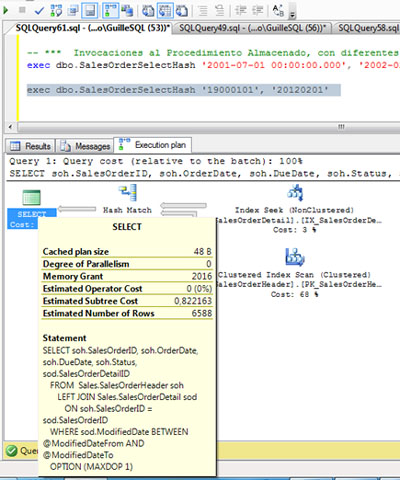
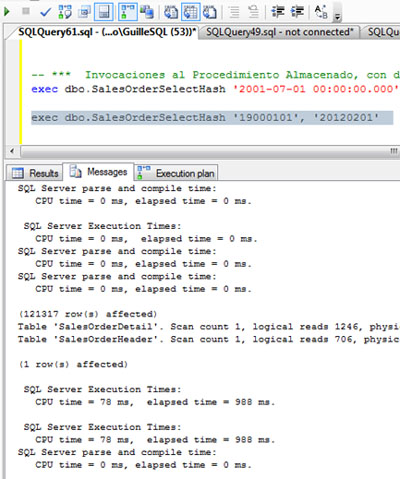
Vamos a ejecutar nuestro Procedimiento Almacenado de ejemplo para un pequeño rango de fechas, con la opción Include Actual Execution Plan habilitada, tal y como se muestra en el siguiente ejemplo. Como podemos observar, el valor de Memory Grant es 2016.
Si nos fijamos en la operación HASH MATCH, el número de filas estimadas y el número de filas actuales (afectadas) es coincidente, por lo que podemos entender que la concesión de memoria para esta consulta (Memory Grant) es apropiada.
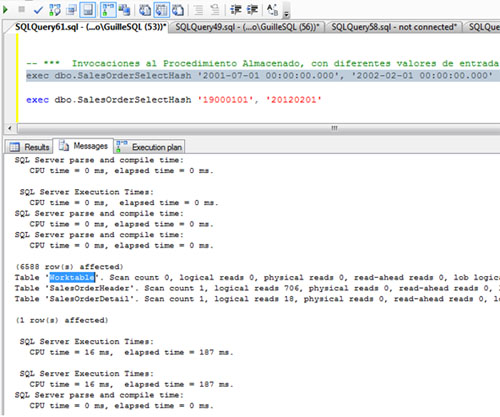
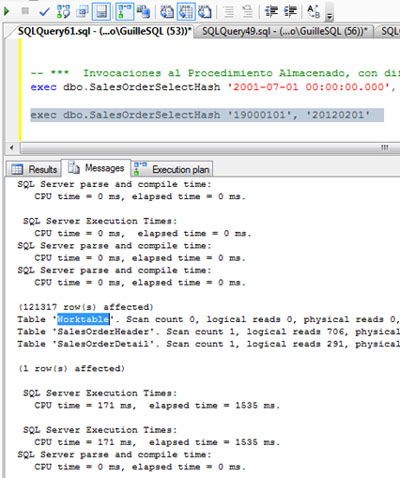
Si revisamos la salida de mensajes teniendo las estadísticas de IO activadas (SET STATISTICS IO ON), podemos observar que se ha creado una Tabla de Trabajo (Work Table) sobre TEMPDB, aunque no se han producido escrituras ni lecturas sobre la misma.
Si volvemos a consultar la DMV sys.dm_io_virtual_file_stats para identificar las lecturas y escrituras realizadas sobre TEMPDB, podremos comprobar que el número de lecturas y escrituras es el mismo que antes de empezar las pruebas, luego no se ha accedido a TEMPDB.
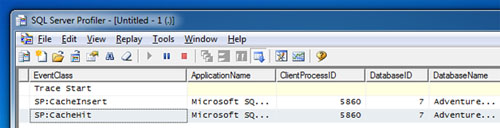
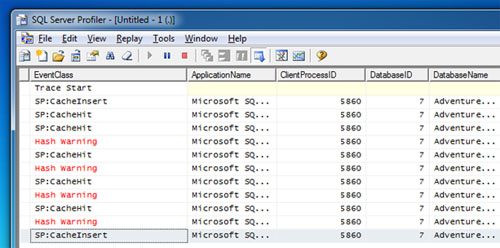
Volvemos a invocar a nuestro procedimiento almacenado con los mismos valores para los parámetros de entrada, obteniendo las mismas conclusiones. Si revisamos la Traza de SQL Profiler, podremos observar que en la primera invocación se generó el Plan de Ejecución y se cacheo en memoria (CacheInsert), mientras que en la segunda ejecución se reutilizó el Plan de Ejecución existente en la Cache (CacheHit).
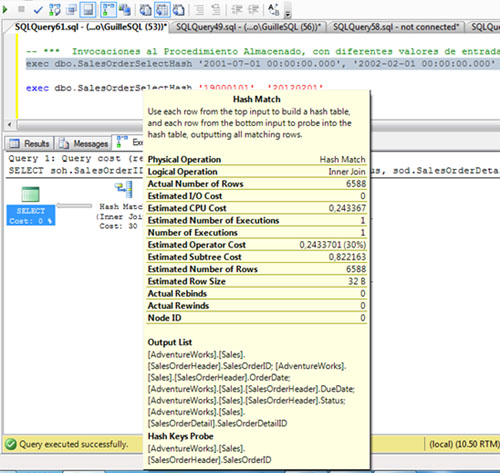
A continuación vamos a invocar a nuestro procedimiento almacenado utilizando unos valores de entrada diferentes, que afectarán a un conjunto de filas mucho más grande. Al revisar el Plan de Ejecución podemos observar que se está utilizando un Plan de Ejecución similar al anterior (mismos Operadores). Además, también se está utilizando el mismo valor de Memory Grant, en este caso de ejemplo, 2016.
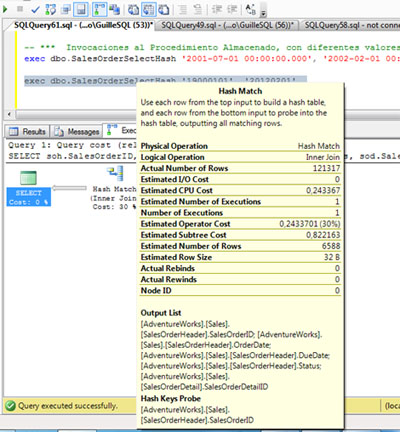
Al revisar la información del operador HASH MATCH, podemos observar que el número de filas estimadas y el número de filas actuales es muy distinto. De hecho, el número de filas estimadas, es el mismo que el de la anterior ejecución, por lo que parece que estamos reutilizando el Plan de Ejecución.
Si revisamos la salida de mensajes teniendo las estadísticas de IO activadas (SET STATISTICS IO ON), podemos observar que se ha creado una Tabla de Trabajo (Work Table) sobre TEMPDB, aunque no se han producido escrituras ni lecturas sobre la misma.
Ejecutamos tres veces más el procedimiento almacenado, manteniendo los valores de entrada utilizados en esta última invocación. Ahora, vamos a revisar nuestra Traza de SQL Profiler. Como parecía evidente, en estas últimas cuatro ejecuciones se ha reutilizado el Plan de Ejecución (CacheHit) provocándose un evento Hash Warning en cada invocación. La ocurrencia de cada evento Hash Warning implica que se ha producido un desbordamiento sobre TEMPDB (spilling to TEMPDB), luego se ha incurrido en un acceso adicional a TEMPDB por este motivo, y no por la utilización de Tablas de Trabajo (Work Tables).
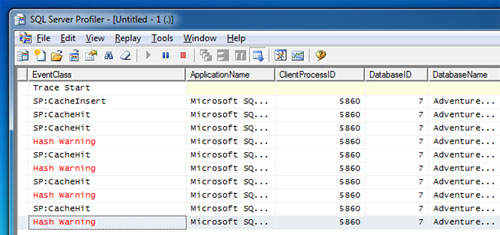
Como era de esperar, TEMPDB se resiente. Estamos utilizando un sencillo caso de ejemplo, y podemos observar que TEMPDB ha necesitado crecer. Ahora pensemos qué efectos puede tener todo esto en un entorno de alta concurrencia y trabajando con grandes volúmenes de datos y múltiples CPUs. SQL Server está reutilizando el Plan de Ejecución, con la esperanza de que el coste de recompilar el procedimiento almacenado sea mayor que reutilizarlo, lo cual, en unas ocasiones es rentable y en otras no.
Si volvemos a consultar la DMV sys.dm_io_virtual_file_stats para identificar las lecturas y escrituras realizadas sobre TEMPDB, podremos comprobar que el número de lecturas y escrituras sobre TEMPDB ha aumentado. De cajón.
Bien. Ya hemos visto como la reutilización del Plan de Ejecución en una consulta sencilla con un INNER JOIN y un BETWEEN, puede generarnos eventos Hash Warning y desbordamiento sobre TEMPDB (spilling to TEMPDB). Pero ¿Qué ocurriría si la primera vez que ejecutamos nuestro procedimiento almacenado lo hacemos con unos valores de entrada que afecten a un gran número de filas? No lo digo, lo hago.
Vamos a vaciar toda la caché de procedimientos almacenados, para lo cual, ejecutaremos el comando DBCC FREEPROCCACHE. Estoy trabajando sobre un entorno de laboratorio, por lo que no hay problema en hacerlo, aunque también podríamos apuntar un poquitín mejor, y utilizar el sp_compile para forzar la próxima compilación de sólo el procedimiento almacenado que nos ocupa. Esto último, más elegante, todo hay que decirlo.
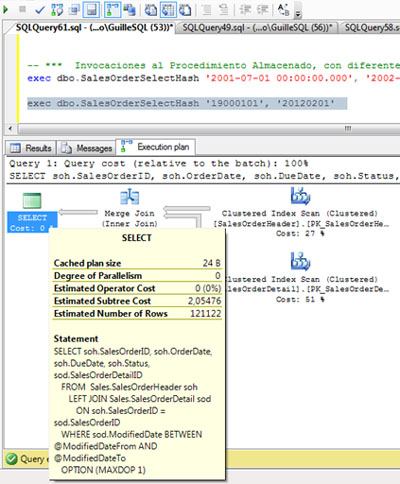
Volvemos a ejecutar nuestro procedimiento almacenado, utilizando unos valores de entrada que afectarán a un gran volumen de filas. Sorpresa: El Plan de Ejecución es diferente, ya que en esta ocasión no se está utilizando el operador Hash Match (que es un Operador Costoso con necesidades adicionales de Memoria de Consulta), para utilizar un operador Merge Join. De hecho, como no estamos utilizando un Operador Costoso, no hay Memory Grant.
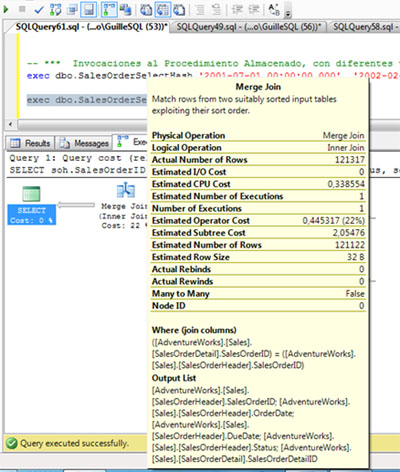
Si revisamos el operador Merge Join del Plan de Ejecución, el número de filas estimadas y actuales es prácticamente coincidente (121122 vs 121317), por lo que podríamos entender que el Plan de Ejecución utilizado es el que le corresponde, para este caso y este número de filas.
Si revisamos la salida de mensajes teniendo las estadísticas de IO activadas (SET STATISTICS IO ON), podemos observar que en esta ocasión NO se ha creado una Tabla de Trabajo (Work Table) sobre TEMPDB, a diferencia de cuando se estaba utilizando el operador Hash Match.
Si volvemos a consultar la DMV sys.dm_io_virtual_file_stats para identificar las lecturas y escrituras realizadas sobre TEMPDB, podremos comprobar que el número de lecturas y escrituras sobre TEMPDB se mantiene, luego no se ha producido ningún acceso a TEMPDB. No hay Tablas de Trabajo (Work Tables) ni desbordamiento sobre TEMPDB (spilling to TEMPDB). Está claro.
Si revisamos la Traza de SQL Profiler, podremos observar que evidentemente no se ha reutilizado el Plan de Ejecución (CacheInsert) y tampoco se ha producido ningún evento Hash Warning.
Y podríamos seguir, ya que si en este momento intentásemos ejecutar nuestro procedimiento almacenado para unos valores de entrada distinto, por ejemplo usando los primeros que afectaban a un pequeño número de filas, volveríamos a reutilizar el Plan de Ejecución, en esta ocasión con el operador Merge Join.
Conclusiones y Script SQL de ejemplo
Como hemos podido ver a lo largo del presente artículo (y del resto de artículos de esta serie), la reutilización de Planes de Ejecución puede jugarnos una mala pasada.
Podría ser que estuviésemos reutilizando un Plan de Ejecución no apropiado porque los Operadores que incluye no sean los apropiados (como el ejemplo que hemos visto con los operadores Merge Join y Hash Match).
También podría ser que estuviésemos reutilizando un Plan de Ejecución con una asignación o concesión de memoria de consulta (Memory Grant) incorrecta (al incluir Operadores Costosos), incurriendo en una subestimación de memoria de consulta con el correspondiente evento Hash Warning / Sort Warning y un desbordamiento sobre TEMPDB (spilling to TEMPDB), o bien incurriendo en una sobrestimación de memoria de consulta (desperdiciando memoria y pudiendo generar esperas innecesarias).
Pero en ambos casos, el problema de fondo es el mismo: SQL Server está reutilizando el Plan de Ejecución, con la esperanza de que el coste de recompilar el procedimiento almacenado sea mayor que reutilizarlo, lo cual, en unas ocasiones es rentable y en otras no.
No podía faltar el Script SQL con el código de ejemplo.
En el próximo artículo podemos ver un ejemplo del evento Sort Warning producido por unas estadísticas incorrectas o poco actualizadas, como contraejemplo al presente artículo, en que hemos reproducido el correspondiente evento como consecuencia de la reutilización del plan de ejecución utilizando unos valores distintos para los parámetros de entrada.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.