Continuando con nuestra serie de artículos sobre Problemas de Rendimiento en SQL Server relacionados con los eventos de traza Hash Warning y Sort Warning, tras entender cómo funcionan las concesiones de memoria de consulta (Memory Grants) en SQL Server y la diferencia entre el acceso a TEMPDB por desbordamiento (spilling to TEMPDB) y las Tablas de Trabajo (Work Tables), y después de ver un ejemplo de Sort Warning al reutilizar el Plan de Ejecución y otro ejemplo de Hash Warning al reutilizar el Plan de ejecución, en esta ocasión vamos a ver un tercer ejemplo, también en esta misma línea.
Al igual que vimos en artículos anteriores, en los cuales forzábamos la ocurrencia de los eventos Hash Warning y Sort Warning al reutilizar un Plan de Ejecución generado para unos valores de parámetros de entrada distintos (que afectaban a un número de filas inferior), el problema de fondo es el mismo: se utiliza un Plan de Ejecución con Operadores Costosos (Expensive Operators) que estimó una cantidad de Memoria de Consulta en función de un número de filas estimadas, y en tiempo de ejecución se descubre que el número de filas afectadas y las necesidades de memoria reales son mucho mayores (subestimación), incurriendo en un desbordamiento sobre TEMPDB (spilling to TEMPDB) para poder ejecutar la consulta en cuestión.
Sin embargo, el ejemplo que se describe en el presente artículo, muestra una estimación incorrecta al generar el Plan de Ejecución debido a unas estadísticas no actualizadas. Sé lo que estas pensando. ¿Cómo simulamos de forma sencilla, en nuestro entorno de laboratorio, un escenario con estadísticas no actualizadas o incorrectas? Buena pregunta. Por suerte, Eladio Rincón (uno de los que saben) en su Post Sort Warning in SQL Server: Complicaciones derivadas del Sort Operator y el Equipo de Optimización de SQL Server en su Post UPDATE STATISTICS undocumented options, lo pensaron antes que nosotros. Así da gusto ;-)
Falsear Estadísticas con UPDATE STATISTICS WITH ROWCOUNT y/o UPDATE STATISTICS WITH PAGECOUNT
Hasta donde yo sé, el Optimizador de Consultas de SQL Server utiliza, entre otras cosas, las estadísticas de campos e índices, para la generación de los Planes de Ejecución. De hecho, en otros motores de base de datos, es habitual promover las estadísticas del entorno de producción, al resto de entornos del ciclo de vida, es decir, a Desarrollo, Calidad, Pre-Producción, y cualquier otro entorno que pudiera existir. De este modo, consiguen obtener en estos entornos, unos Planes de Ejecución congruentes a los que se obtendrán en producción, aunque evidentemente, dado que los datos no son los mismos, el resultado de la ejecución podrá no ser representativo en muchos casos.
Volviendo al tema que nos ocupa, en nuestro caso vamos a falsear las estadísticas para simular un servidor con estadísticas poco actualizadas, y evidenciar como por culpa de dichas estadísticas erróneas, se pueden generar eventos Hash Warning y Sort Warning.
Para falsear las estadísticas de SQL Server vamos a utilizar el comando no documentado UPDATE STATISTICS WITH ROWCOUNT, para de este modo, decirle a SQL Server que el número de filas de la tabla deseada es el que nosotros nos inventemos. También podríamos utilizar el comando no documentado UPDATE STATISTICS WITH PAGECOUNT, aunque en nuestro caso de ejemplo utilizaremos el ROWCOUNT.
Por otro lado, tenemos un Plan de Mantenimiento que realiza una Reindexación completa de la base de datos de Adventure Works. Como sabemos, la Reindexación también actualiza las estadísticas (de hecho, esta es una de las diferencias entre reindexar o defragmentar índices). Por lo tanto, después de jugar con el UPDATE STATISTICS WITH ROWCOUNT, si lo deseamos, podemos ejecutar este Job del Plan de Mantenimiento para volver a dejar las estadísticas en buen estado, a través de dicha Reindexación.
Preparando el entorno de Laboratorio
Partimos de una instancia SQL Server 2008 R2, con la base de datos de Adventure Works instalada. Para nuestro ejemplo, hemos creado un índice sobre la tabla que deseamos consultar, que eliminaremos al finalizar nuestras pruebas. Seguidamente hemos creado un procedimiento almacenado (dbo.SalesOrderSelect), el cual devuelve un conjunto de filas ordenado realizando un ORDER BY, y filtrando por un rango de fechas (BETWEEN) que se especifican como parámetros de entrada de dicho Procedimiento Almacenado. Como siempre, al final del artículo podéis descargar el Script SQL con todo el código de ejemplo.
Para continuar, deberemos abrir el SQL Profiler, y ejecutar una traza para capturar las ocurrencias de los siguientes Eventos:
- Errors and Warnings - Hash Warning
- Errors and Warnings - Sort Warnings
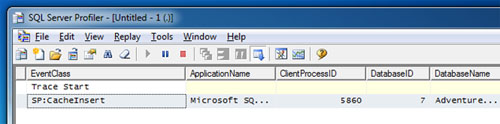
- Stored Procedures – SP:CacheHit
- Stored Procedures – SP:CacheInsert
Reducimos TEMPDB al menor tamaño posible. En nuestro caso de ejemplo, el MDF de TEMPDB ocupa tan sólo 1,5MB.
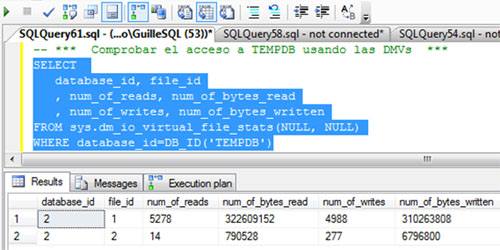
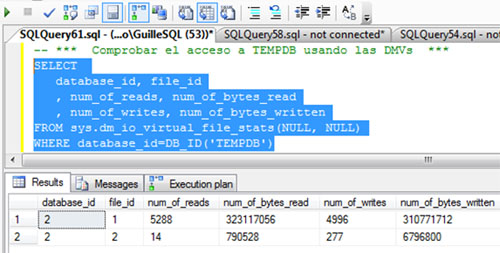
Además, vamos a consultar la DMV sys.dm_io_virtual_file_stats, para identificar las lecturas y escrituras realizadas sobre TEMPDB, y de este modo, poder tener otra medida que nos indique si se ha incurrido en un acceso a TEMPDB o no. En la siguiente pantalla capturada se muestra la consulta realizada y la salida obtenida.
Ejecución de las Pruebas para reproducir el evento Sort Warning y falseo de las Estadísticas
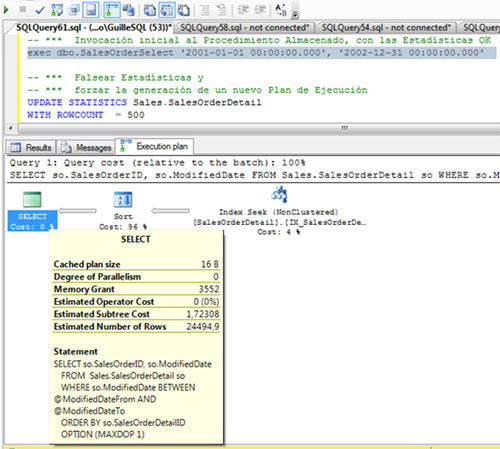
Vamos a ejecutar nuestro Procedimiento Almacenado de ejemplo en un escenario con las estadísticas correctas (donde sufrimos reindexaciones frecuentes de nuestra base de datos, lo cual, mantiene actualizadas las estadísticas), utilizando la opción Include Actual Execution Plan habilitada, tal y como se muestra en el siguiente ejemplo. Como podemos observar, el valor de Memory Grant es 3552.
Si nos fijamos en la operación SORT, el número de filas estimadas y el número de filas actuales (afectadas) es prácticamente coincidente (24504 vs 24494), por lo que podemos entender que la concesión de memoria para esta consulta (Memory Grant) es apropiada.
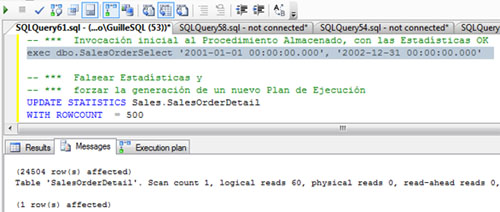
Si revisamos la salida de mensajes teniendo las estadísticas de IO activadas (SET STATISTICS IO ON), podemos observar que NO se ha creado ninguna Tabla de Trabajo (Work Table) sobre TEMPDB.
Si volvemos a consultar la DMV sys.dm_io_virtual_file_stats para identificar las lecturas y escrituras realizadas sobre TEMPDB, podremos comprobar que el número de lecturas y escrituras es el mismo que antes de empezar las pruebas, luego no se ha accedido a TEMPDB.
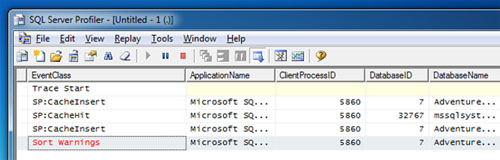
Si revisamos la Traza de SQL Profiler, podremos observar que en esta primera invocación se generó el Plan de Ejecución y se cacheo en memoria (CacheInsert). Además, no se ha producido ningún evento Hash Warning ni Sort Warning.
Hasta aquí todo normal, al menos, para un entorno que mantiene sus estadísticas correctamente actualizadas.
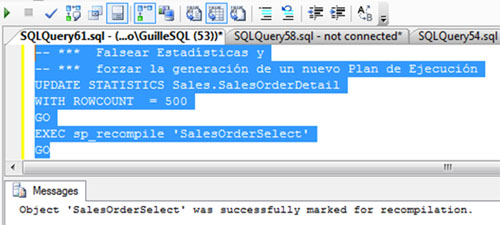
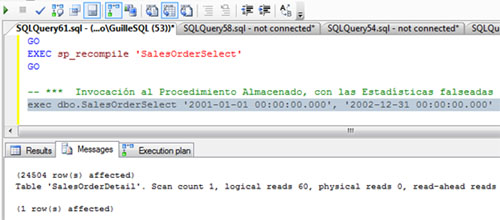
Ahora llega el contraejemplo. Lo primero, vamos a falsear las estadísticas de SQL Server utilizando el comando no documentado UPDATE STATISTICS WITH ROWCOUNT, para seguidamente forzar la generación de un nuevo Plan de Ejecución para nuestro procedimiento almacenado de ejemplo a través del sp_recompile. Esto se muestra en la siguiente pantalla capturada.
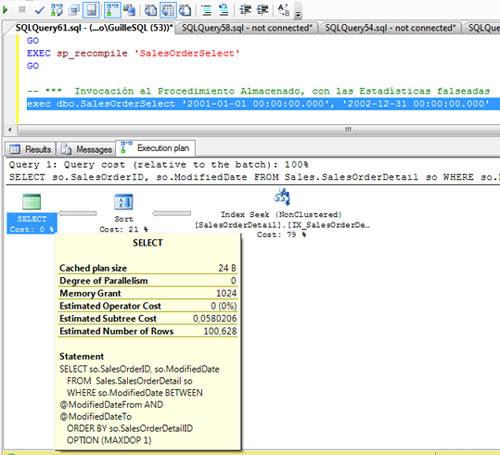
Volvemos a ejecutar nuestro procedimiento almacenado de ejemplo, incluso con exactamente los mismos valores para los parámetros de entrada. Sin embargo, en esta ocasión, al generarse el nuevo Plan de Ejecución, el Optimizador de Consultas de SQL Server está teniendo en cuenta las actuales (y erróneas) estadísticas. Y esto se nota. Para esta segunda invocación en situación de estadísticas no actualizadas, el valor de Memory Grant es 1024 en lugar de 3052.
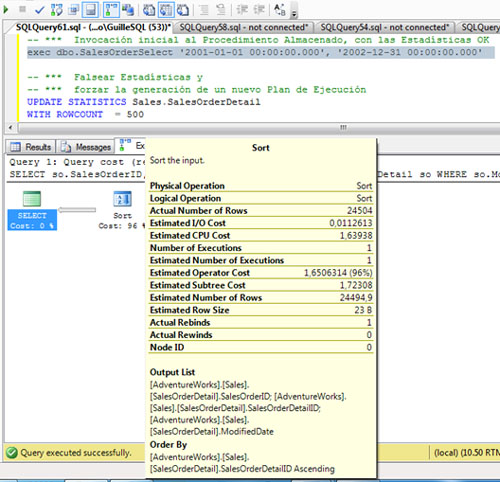
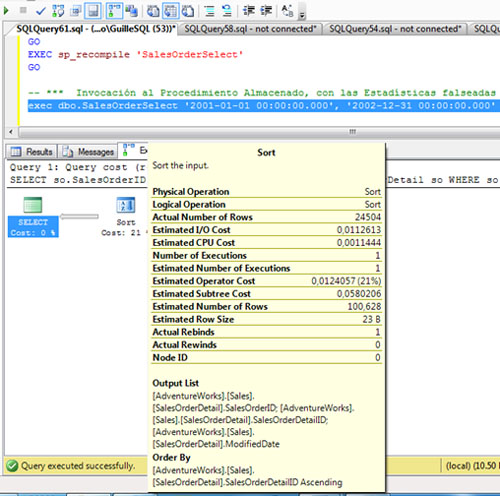
Si nos fijamos en la operación SORT, el número de filas estimadas y el número de filas actuales (afectadas) es completamente diferente (24504 vs 100), lo que justifica que la concesión de memoria (Memory Grant) para esta invocación NO sea la apropiada.
Si revisamos la salida de mensajes, de nuevo no se ha utilizado ninguna Tabla de Trabajo (Work Table).
Aunque sin embargo, si volvemos a consultar la DMV sys.dm_io_virtual_file_stats para identificar las lecturas y escrituras realizadas sobre TEMPDB, podremos comprobar que el número de lecturas y escrituras sobre TEMPDB ha aumentado, pero como hemos visto, esto no ha sido por la creación de Tablas de Trabajo (Work Tables). ¿Por qué ha sido?
Al revisar nuestra Traza de SQL Profiler, podemos ver que se ha producido un evento Sort Warning. Cáspita !!! De nuevo, hemos sufrido un desbordamiento sobre TEMPDB (spilling to TEMPDB) por una subestimación de memoria de consulta, aunque en esta ocasión, no ha sido por la reutilización del Plan de Ejecución, sino por la existencia de estadísticas mal actualizadas.
Era de temer. El tamaño del fichero de datos de TEMPDB ahora es mayor que al principio del artículo.
Conclusiones y Script SQL de ejemplo
A través del presente artículo hemos pretendido mostrar como la existencia de estadísticas poco actualizadas y la necesidad de generar Planes de Ejecución con Operadores Costosos (Expensive Operators) que requieran de concesiones de Memoria de Consulta (Memory Grants), puede facilitar la creación de eventos de Hash Warning y Sort Warning, debido a que el Optimizador de Consultas de SQL Server genera el Plan de Ejecución utilizando las (incorrectas) estadísticas de que dispone. En este escenario, se crea un Plan de Ejecución que asume un número de filas (estimadas), y al ejecutarse la consulta descubre que el número de filas reales es muy diferente, lo cual, puede provocar problemas de subestimación de memoria (y en consecuencia, eventos Hash Warning y Sort Warning) o de sobrestimación de memoria (despilfarrando memoria). En esta ocasión, no estamos sufriendo una reutilización del Plan de Ejecución, pero igualmente, incurrimos en los mismos problemas de estimación de memoria que vimos en los anteriores artículos de esta serie.
Como en casos anteriores, no podía faltar el Script SQL con el código de ejemplo.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.